GPU架构发展历史
| 架构 | 发布年份 | 特点 | 典型芯片 | 芯片制程 |
|---|---|---|---|---|
| Tesla | 2006 | 首个通用GPU计算架构 | GeForce 8800 Ultra | |
| Fermi | 2009 | 首款采用40nm制程的GPU | GeForce GTX 590 | 40nm |
| Kepler | 2012 | 首个支持超级计算和双精度计算的GPU架构 | GeForce GTX 770 | 28nm |
| Maxwell | 2014 | 在功耗效率、计算密度上获得重大提升 | GeForce GTX 750 Ti | 28nm |
| Pascal | 2016 | 大大增强了GPU的能效比和计算密度 | Tesla P100 | 16nm |
| Volta | 2017 | 增加了Tensor核心 | Tesla V100 | 12nm |
| 架构 | 发布年份 | 特点 | 典型芯片 | 芯片制程 |
|---|---|---|---|---|
| Turing | 2018 | 配备了名为 RT Core 的专用光线追踪处理器 |
T1000 | 12nm |
| Ampere | 2020 | 有史以来最大的 7nm芯片 | A100(7nm) | 7nm 8nm(30系列) |
| Hopper | 2021 | 通过Transformer引擎推进 Tensor Core技术的发展 |
H100 | 5nm |
| Ada Lovelace | 2022 | 为光线追踪和基于 AI 的神经图形提供革命性的性能 | 4090 | 5nm |
GPU架构
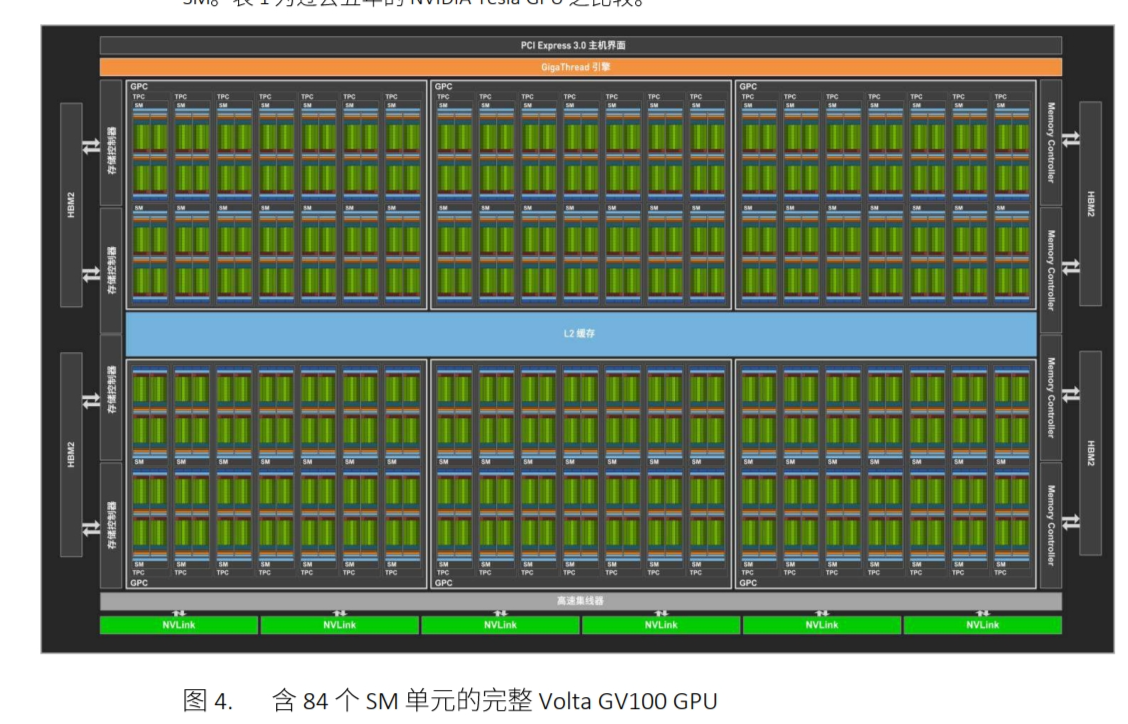
SM(Streaming Multiprocessor):流式多处理器
为计算单元,作用为执行计算。每一个SM都有自己的控制单元(Control Unit),寄存器(Register),缓存(Cache),指令流水线(execution pipelines)。

线程束调度器(Warp Scheduler)顾名思义是进行线程束的调度,负责将软件线程分配到计算核上;LDU(Load-Store Units)负责将值加载到内存或从内存中加载值;SFU(Special-Function Units)用来处理sin、cos、求倒数、开平方特殊函数。
共享内存和全局内存
共享内存(Shared memory)是位于每个流处理器组(SM)中的高速内存空间,主要作用是存放一个线程块(Block)中所有线程都会频繁访问的数据。流处理器(SP)访问它的速度仅比寄存器(Register)慢,它的速度远比全局显存快。但是他也是相当宝贵的资源,一般只有几十KByte。
GPU的全局内存之所以是全局的,主要是因为GPU与CPU都可以对它进行写操作。任何设备都可以通过PCI-E总线对其进行访问。GPU之间不通过CPU,直接将数据从一块GPU卡上的数据传输到另一个GPU卡上。
GPU加速原理
神经网络非常依赖矩阵运算,同时需要出色的浮点计算性能和带宽,英伟达GPU拥有成千上万个专为矩阵运算而优化的矩阵核心。
计算精度基本知识
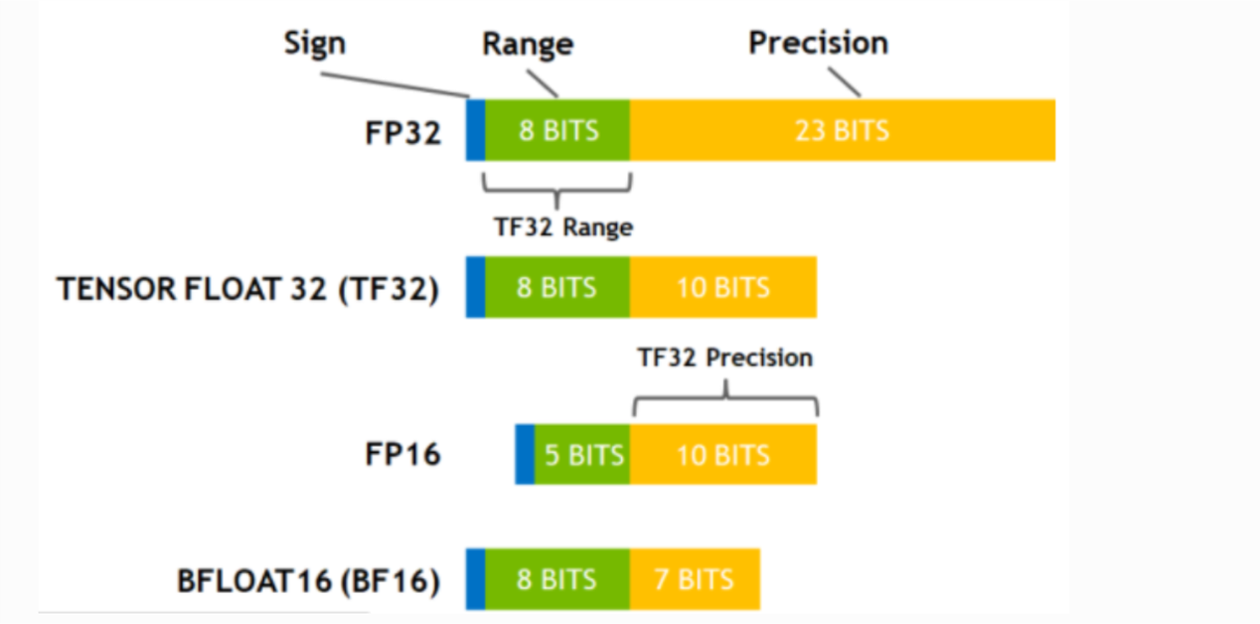
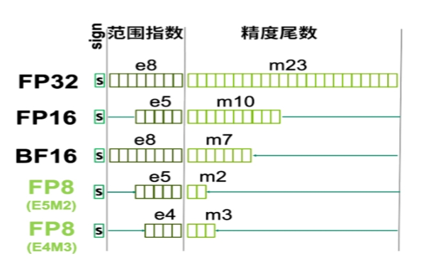
FP32、TF32、FP16、BF16、FP8
性能指标
FLOPS(Floating-point operations per second)
每秒浮点运算次数(亦称每秒峰值速度)是每秒所运行的浮点运算次数;
一个MFLOPS(megaFLOPS)等于每秒一百万(10^6)次的浮点运算;
一个GFLOPS(gigaFLOPS)等于每秒十亿(10^9)次的浮点运算;
一个TFLOPS(teraFLOPS)等于每秒一兆/一万亿(10^12)次的浮点运算;
一个PFLOPS(petaFLOPS)等于每秒一千兆/一千万亿(10^15)次的浮点运算;
一个EFLOPS(exaFLOPS)等于每秒一百京/一百亿亿(10^18)次的浮点运算;
TOPS(Tera Operations Per Second)
1TOPS代表处理器每秒钟可进行一万亿次(10^12)操作。
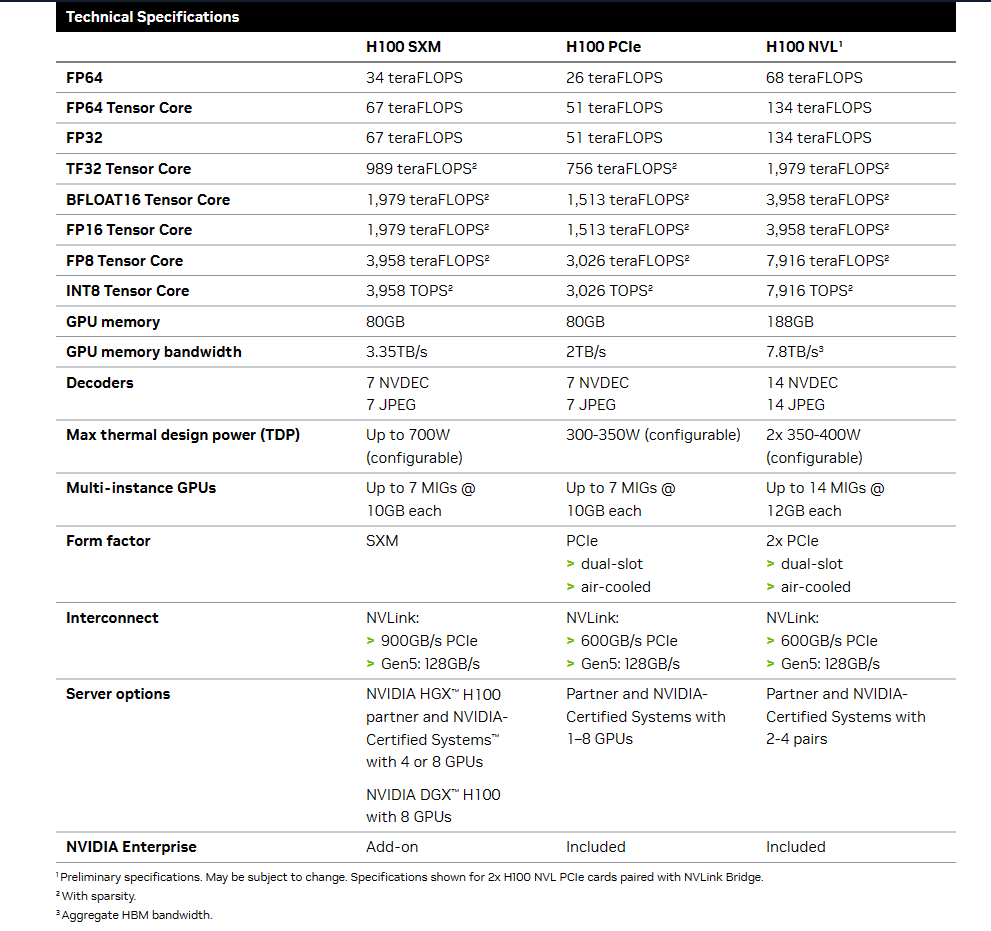
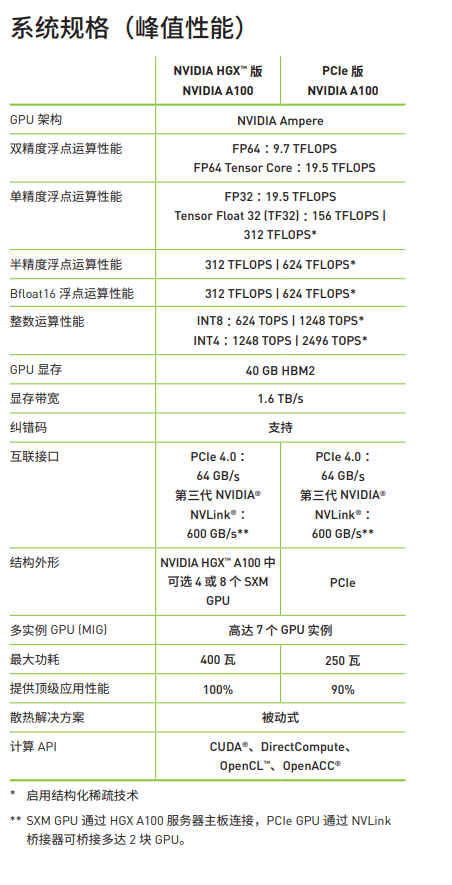
H100计算性能
A100计算性能’
游戏显卡计算性能
桌面级显卡性能排行榜 - 芯参数 (xincanshu.com)
CUDA
2006年NVIDIA推出以CUDA为核心的GPU,拉开了一个时代的序幕。CUDA是一种通用并行计算架构,而深度学习,强化学习需要大量且复杂的计算,CUDA的架构大大提高了运算速率,而且CUDA核心数量越多并行计算的能力越大,简单理解,之前需要一年的计算量,CUDA推出之后仅需一天。
Tensor core
2017年引入Tensor Core(RTX系列),为大模型的出现奠定了坚实的基础,这也是专为深度学习所设计。深度学习所采用的核心计算主要由张量和矩阵组成,而Tensor Core为了他们专门设计了执行单元。
GTX到RTX:RTX20显卡采用的“图灵”架构引入了RT core计算单元,使其光线追踪性能超越上一代显卡的六倍,拥有了即时处理游戏光追的条件,NVIDIA认为这是一个划时代的进化,于是把沿用多年的“GTX”改名为“RTX”。
Transformer引擎:新的 Transformer 引擎结合了软件和定制的 Hopper Tensor Core 技术,专门用于加速Transformer 模型的训练和推理。
Tensor core介绍
Tensor Core中计算详情
矩阵-矩阵乘法(GEMM)(General Matrix Multiplication)是神经网络训练和推理的核心。它可以在一个时钟周期内完成两个半精度浮点矩阵的乘法(64 GEMM per clock)(此处的矩阵乘法是叉乘,参考链接。
每个Tensor核心可以在一个时钟周期内完成64次浮点FMA运算(V100)。A100 Tensor Core每个时钟可以执行 256 个 FP16 FMA操作。(4 * 8 矩阵 × 8 * 8矩阵)
注:FMA运算(fused multiply-add):乘法加法混合运算
在一代tensor core和二代tensor core中,每个Tensor Core都在4×4矩阵中运行。每个Tensor核都在4×4的矩阵中运行,并执行D=A×B+C这样的运算,其中A、B、C和D都为4×4矩阵,其中A和B为FP16矩阵,C和D可以为FP16或FP32矩阵。
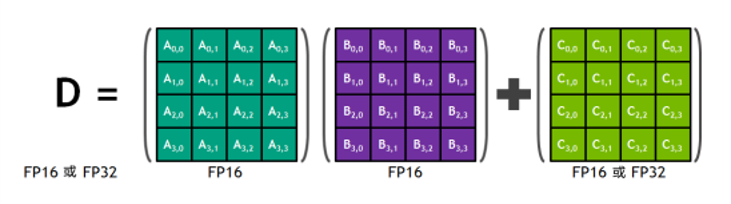
混合精度乘积累加运算
Tensor核心在FP16输入数据和FP32累加运算时都会发挥作用。先使用FP16乘积得到全精度乘积,然后使用FP32累加将该乘积与其他中间乘积相加。(混合精度乘积累加运算)

Tensor Core发展历史
Volta Tensor Core:通过 FP16 和 FP32 下的混合精度矩阵乘法提供了突破性的性能,配备Volta Tensor核心的Volta V100对于矩阵乘法的计算速度比Pascal P100快12倍。
Turing Tensor Core:Turing Tensor 核心设计添加了INT8、INT4和INT1精度模式,其矩阵计算方式与Volta相同。(此处吞吐量可认为与计算速度等同)
Ampere Tensor Core:Ampere Tensor核心增加TF32、BF16和FP64模式。相比于Volta Tensor核心,Ampere中的D=A×B+C,其中 C 和 D 是m×n矩阵,A是m×k 矩阵,B是k×n矩阵。与传统的FP32相比,A100的FP16吞吐量是V100(Volta)的20倍,TF32是FP32的5倍,FP6为2.5倍,INT8为20倍。利用了深度学习网络中的细粒度结构化稀疏性,使标准 Tensor核心操作的性能提高了一倍。
Hopper Tensor Core:Hopper Tensor核心增加了FP8格式,可加速 AI 训练和推理。o采用新的Transformer引擎可结合使用FP8和FP16 精度,减少内存使用并提高性能,同时仍能保持大型语言模型和其他模型的准确性。与Ampere Tensor核心相比,Hopper Tensor核心FP16吞吐量为快3倍,若使用FP8达到6倍,TF32、FP64和INT8为3倍。
显卡计算能力
计算能力对应
| 显卡类型 | 计算能力 |
|---|---|
| RTX 4080 | 8.9 |
| RTX 3080 | 8.6 |
| RTX 2080 | 7.5 |
| RTX 2060 | 7.5 |
| RTX1080Ti | 6.1 |
数据来源: CUDA GPUs - Compute Capability | NVIDIA Developer
计算能力详解
| 功能支持 | 5.0,5.2 | 5.3 | 6.x | 7.x | 8.x | 9.0 |
|---|---|---|---|---|---|---|
| 全局内存 int32 | Y | Y | Y | Y | Y | Y |
| 共享内存 int32 | Y | Y | Y | Y | Y | Y |
| 全局内存 int64 | Y | Y | Y | Y | Y | Y |
| 共享内存 int64 | Y | Y | Y | Y | Y | Y |
| 全局内存 int128 | N | Y | Y | Y | Y | Y |
| 共享内存 int128 | N | Y | Y | Y | Y | Y |
| 共享内存 原子加 float32 | Y | Y | Y | Y | Y | Y |
| 共享内存 原子加 float64 | N | N | Y | Y | Y | Y |
| 全局内存 原子加 float2或float4 | N | N | N | N | N | Y |
| 半精度浮点数 | N | Y | Y | Y | Y | Y |
| Bfloat16 | N | N | N | N | Y | Y |
6.x
64 个(计算能力 6.0)或 128 个(6.1 和 6.2)个用于算术运算的 CUDA 内核,
16 个 (6.0) 或 32 个(6.1 和 6.2)个特殊函数单元,用于单精度浮点超越函数( transcendental functions,)
2 个 (6.0) 或 4 个(6.1 和 6.2)翘曲调度器(warp schedulers.)。
7.x
64 个 FP32 内核,用于单精度算术运算,
32 个 FP64 内核,用于双精度算术运算,
64 个 INT32 内核,用于整数数学运算,
8 个混合精度的 Tensor Core,用于深度学习矩阵运算
16 个特殊函数单元,用于单精度浮点超越函数,
4 个 warp 调度器。
8.x
64 个 FP32 内核,用于计算能力为 8.0 的设备中的单精度算术运算,以及计算能力为 128.32、8.6 和 8.7 的设备中的 8 个 FP9 内核,
32 个 FP64 内核,用于计算能力 8.0 的设备中的双精度算术运算,以及计算能力为 2.64、8.6 和 8.7 的设备中的 8 个 FP9 内核
64 个 INT32 内核,用于整数数学运算,
4 个混合精度的第三代 Tensor Core,支持半精度 (fp16)、
__nv_bfloat16,tf32, 亚字节(sub-byte)和双精度 (fp64) 矩阵算法,用于计算能力 8.0、8.6 和 8.7(详见 Warp 矩阵函数)()4 个混合精度的第四代 Tensor Core,支持 fp8
,fp16,__nv_bfloat16,tf32和 8.9 的计算能力fp64(详见 [Warp 矩阵函数](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#wmma)),16 个特殊函数单元,用于单精度浮点超越函数,
4 个 warp 调度器。
混合精度训练通过以半精度格式执行运算来提供显着的计算加速,同时以单精度存储最少的信息,以在网络的关键部分保留尽可能多的信息。自从在 Volta 和 Turing 架构中引入 Tensor Core 以来,通过切换到混合精度,训练速度得到了显著提升——在算术强度最高的模型架构上,整体速度提高了 3 倍。
各显卡性能对比
| 显卡 | cuda core | tensor core | fp16 | fp32 | fp64 |
|---|---|---|---|---|---|
| 2060 | 1920 | 240 | 12.90TFLOPS | 6.451TFLOPS | 201.6GFLOPS |
| 2080 | 2944 | 368 | 20.14TFLOPS | 10.07TFLOPS | 314.6GFLOPS |
| 3080 | 8960(12GB)/8704(10GB) | 272 | 29.77TFLOPS | 29.77TFLOPS | 465.1GFLOPS |
| 4080 | 9728 | 304 | 48.74TFLOPS | 48.74TFLOPS | 761.5GFLOPS |
数据来源:(30系以前)芯参数GPU显卡性能数据库
4080: CUDA GPUs - Compute Capability | NVIDIA Developer
NVlink
HBM
H100 VS A100
.png)
.png)
数据来源:NVIDIA H100 Tensor Core GPU Architecture Overview
计算峰值
理论值

实测值

问题集锦
Q1:计算显卡(特斯拉)与游戏显卡是否有支持计算精度的差别?
| CUDA Compute Capability | Example Device | TF32 | FP32 | FP16 | INT8 | FP16 Tensor Cores | INT8 Tensor Cores | DLA |
|---|---|---|---|---|---|---|---|---|
| 9.0 | NVIDIA H100 | Yes | Yes | Yes | Yes | Yes | Yes | No |
| 8.9 | NVIDIA RTX 4090 4080 | Yes | Yes | Yes | Yes | Yes | Yes | No |
| 8.7 | NVIDIA DRIVE AGX Orin™ | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| 8.6 | 3080 | Yes | Yes | Yes | Yes | Yes | Yes | No |
| 8.0 | NVIDIA A100/GA100 GPU | Yes | Yes | Yes | Yes | Yes | Yes | No |
| 7.5 | 2060 2080 | No | Yes | Yes | Yes | Yes | Yes | No |
| 7.2 | Jetson AGX Xavier | No | Yes | Yes | Yes | Yes | Yes | Yes |
| 7.0 | NVIDIA V100 | No | Yes | Yes | Yes | Yes | No | No |
| 显卡类型 | 计算能力 |
|---|---|
| RTX 4080(Ada) | 8.9 |
| RTX 3080(Ampere) | 8.6 |
| RTX 2080(Turing) | 7.5 |
| RTX 2060(Turing) | 7.5 |
| RTX1080Ti(Pascal) | 6.1 |
不同tensor core支持的计算精度
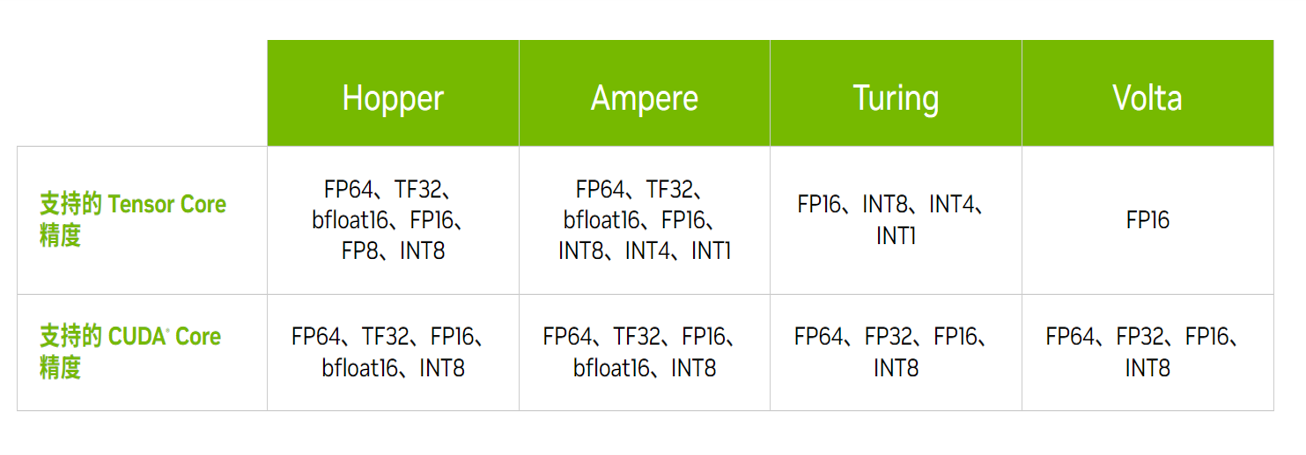
注:NVIDIA DLA(Deep Learning Accelerator–深度学习加速器)是一款针对深度学习操作的固定功能加速器引擎。 DLA 旨在对卷积神经网络进行全硬件加速。 DLA支持卷积、反卷积、全连接、激活、池化、批量归一化等各种层,DLA不支持Explicit Quantization 。
计算精度核心差距
64 个 FP32 内核,用于计算能力为 8.0 的设备中的单精度算术运算,以及计算能力为 8.6、8.7 和 8.9 的设备中的 128 个 FP32 内核,
32 个 FP64 内核,用于计算能力 8.0 的设备中的双精度算术运算,以及计算能力为 8.6、8.7 和 8.9 的设备中的 2 个 FP64 内核
结论:对于游戏显卡和特斯拉计算卡,是否支持精度需要看其计算能力的不同,以八代计算能力为例,A100的8.0 3080的8.6,在INT8 FP16的支持程度是相同的,但是具体计算性能可能有所不同,计算卡和游戏卡最明显的差距是在双精度(fp64)计算上,同时,在第八代计算上,8.0、8.5、8.6同样说明支持第三代tensor core,也就是说,他们支持的计算精度一直。
Q2 :不同计算精度支持的计算精度汇总
6.x
64 个(计算能力 6.0)或 128 个(6.1 和 6.2)个用于算术运算的 CUDA 内核,
16 个 (6.0) 或 32 个(6.1 和 6.2)个特殊函数单元,用于单精度浮点超越函数,
2 个 (6.0) 或 4 个(6.1 和 6.2)warp调度器。
7.x
64 个 FP32 内核,用于单精度算术运算,
32 个 FP64 内核,用于双精度算术运算,34
64 个 INT32 内核,用于整数数学运算,
8 个混合精度的 Tensor Core,用于深度学习矩阵运算
16 个用于单精度浮点超越函数的特殊函数单元,
4 个 warp 调度器。
8.x
64 个 FP32 内核,用于计算能力为 8.0 的设备中的单精度算术运算,以及计算能力为 8.6、8.7 和 8.9 的设备中的 128 个 FP32 内核,
32 个 FP64 内核,用于计算能力 8.0 的设备中的双精度算术运算,以及计算能力为 8.6、8.7 和 8.9 的设备中的 2 个 FP64 内核
64 个 INT32 内核,用于整数数学运算,
4 个混合精度的第三代 Tensor Core,支持半精度 (fp16)、、亚字节和双精度 (fp64) 矩阵算法,用于计算能力 8.0、8.6 和 8.7(详见 Warp 矩阵函数),
__nv_bfloat16``tf324 个混合精度的第四代 Tensor Core,支持 、 、 、 亚字节和 8.9 的计算能力(详见 Warp 矩阵函数),
fp8``fp16``__nv_bfloat16``tf32``fp6416 个用于单精度浮点超越函数的特殊函数单元,
4 个 warp 调度器。
Q3:查看cuda多线程和解码器的排队问题不同SM之间调用的冲突问题
SM如何管理调度线程块呢?首先我们知道线程块中的线程数量是不确定的,所以不能直接以线程块为处理单位。这时引入了wrap线程束概念,每32个线程为一组,被称为线程束。
有多少个线程束调度器就能同时执行多少个线程束,Fermi架构有两个线程束调度器,Kepler架构有四个线程束调度器。
线程束是并行处理的基本单元,线程束中的所有线程同时执行相同的指令!线程束的执行方式被称为单指令多线程
- 每个线程都有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径(单指令多数据,那么全部执行,那么全部不执行,不支持if语句。而单指令多线程可以部分执行)
设想一个非常简单的if语句if (cond) {……} else {……}。假设在一个线程束中有16个线程cond为true,但对于其他16个来说cond为false。这意味着一半的线程束需要执行if语句块中的指令,而另一半需要执行else语句块中的指令。 在同一线程束中的线程执行不同的指令,被称为线程束分化。
由于线程束是单指令多线程的执行,所以不支持16个线程执行if语句块,另外16个线程执行else语句块。那么当发生线程束分化时,线程束中16个线程执行if,冻结另外16个线程;然后,16个线程执行else,冻结另外16个线程。if语句变成了两步走,线程束分化会导致性能明显地下降。
线程网格(grid)、线程块(block)、线程束(warp)
线程束(warp):线程束是GPU的基本执行单位。每个线程束中的线程同时执行,在理想情况下,获得当前指令只需要一次访存,然后将指令广播到这个线程束所占用的所有SP中。当前,GPU上的一个线程束的大小为32。
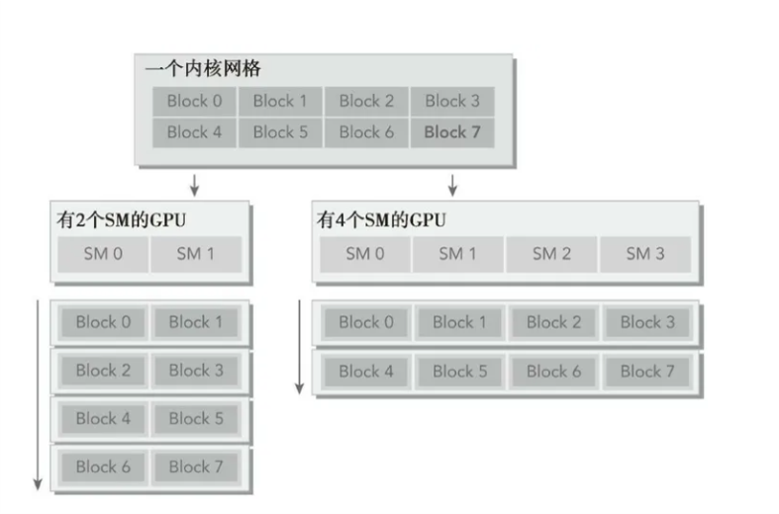
Grid,Block,thread都是线程的组织形式,最小的逻辑单位是一个thread,最小的硬件执行单位是thread warp,若干个thread组成一个block,block被加载到SM上运行,多个block组成一个Grid。
block是常驻在SM上的,一个SM可能有一个或者多个Block,具体根据资源占用分析。
kernel(指的是在GPU上执行的函数)在执行时会以一个grid为整体,划分若干个block,然后将block分配给SM进行运算。block中的线程以32个为一组,称为warp,进行分组计算。block会以连续的方式划分warp。例如,如果一个block由64个thread,则分为2组warp。0-31为warp0,32-63为warp1.如果block不是32的倍数,则多余的thread独立分成一组warp。例如block有65个thread,则最后一个thread单独为一个warp,那么此时这个warp中的其他thread处于非活动状态。
- 在一个block内的warp次序是未定义的,但通过协调全局或者共享内存的存取,它们可以同步的执行。如果一个通过warp 线程执行的指令写入全局或共享内存的同一位置,写的次序是未定义的。
- 在一个grid内的block次序是未定义的,并且在block之间不存在同步机制,因此来自同一个grid的二个不同block的线程不能通过全局内存彼此安全地通讯。
线程块的调度
在线程块调度者为每个SM初始化分配了线程块之后,就会处于闲置状态,直到有线程块执行完毕。当线程块执行完毕之后就会从SM中撤出,并释放其占用的资源。由于线程块都是相同的大小,因此一个线程块从SM中撤出后另一个在等待队列中的线程块就会被调度执行。所有的线程块的执行顺序是随机、不确定的。因此,当我们在编写一个程序解决一个问题的时候,不要假定线程块的执行顺序,因为线程块根本就不会按照我们所想的顺序去执行。
保证在每个GPU中,线程块的数目都是SM数目的整数倍,以此提高设备的利用率。
- 一个线程块只能分配到一个SM上(不存在一个线程块分配到多个SM上)
- 多个线程块可以分配到同一个SM上(因为有可能大多数SM忙,少数SM空闲)
- 每个线程都有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径(单指令多数据,那么全部执行,那么全部不执行,不支持if语句。而单指令多线程可以部分执行)

