写在前面
距离上次上传文章已经过了快半年了,想想这半年或许有些懈怠,不过这半年确实有些浑浑噩噩,无论是实验室的项目、论文,还是一些生活上的小事,都过于劳费心神了,当初博客的规划也完成的七零八落的,当时计划开一个读书感想,想想这半年读的书也少了,想想以前的东西,倒有一种提笔忘字的感觉。也不排除当时是刚买来域名,图一个新鲜感。安静思考下来,倒是觉得浪费青春了,想得太多做的太少,又常常羡慕一些大佬的才华,却又少了一些踏实的行动,实非不可举。
跳过前面的煽情的部分,这篇文章的第二部分及其之后的内容尚未更新结束,第四部分已经出现在计划表半个月了,至今还是寥寥数笔,还是太懈怠了,希望发完之后能起个督促作用吧。再次感谢谭升大佬的博客,对于一个初学者来说,这篇博客解答了很多我的疑惑,也成功带我开始走进CUDA的世界。
CUDA硬件结构
基本架构
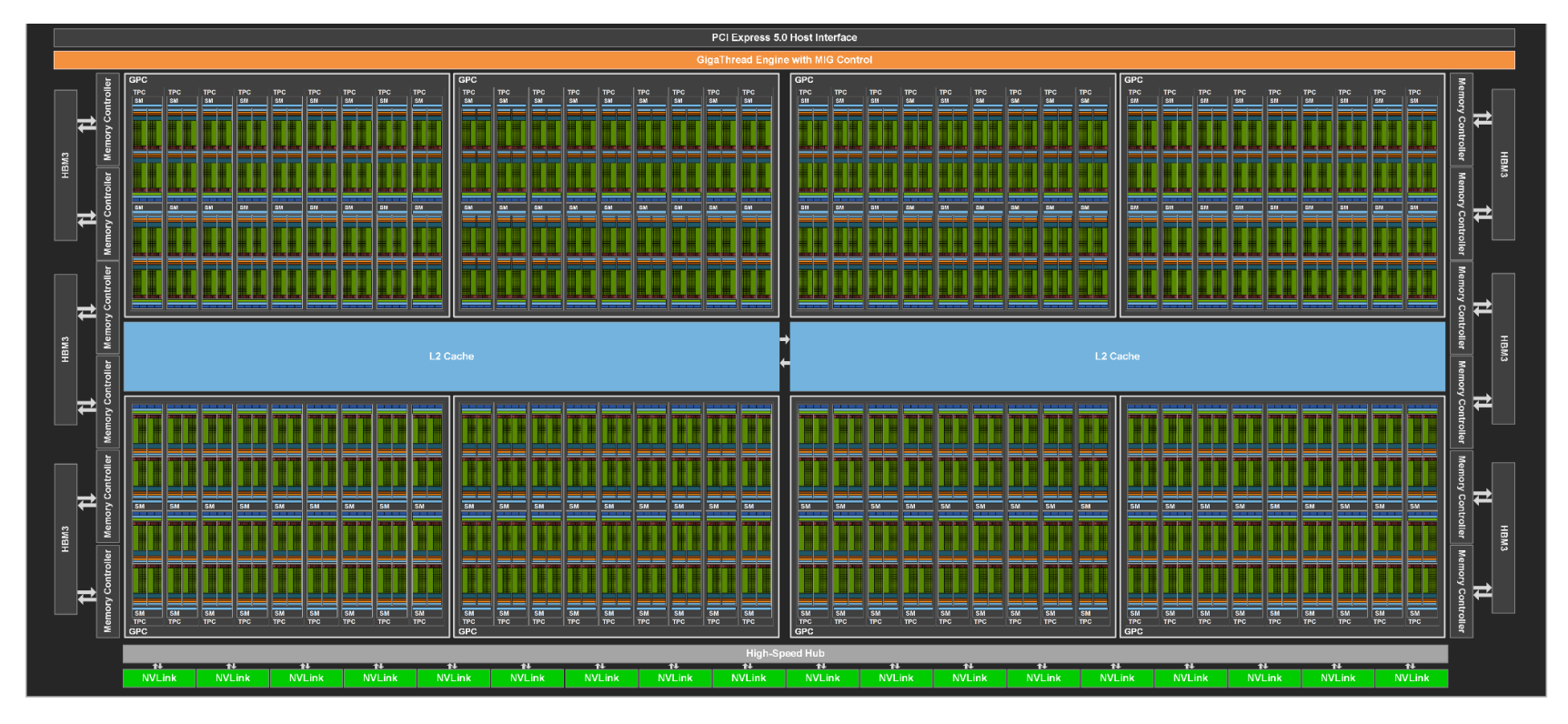
各部分具体结构
HBM
HBM全称为High Bandwidth Memory,即高带宽内存,是一款新型的CPU/GPU内存芯片。 其实就是将很多个DDR芯片堆叠在一起后和GPU封装在一起,实现大容量、高位宽的DDR组合阵列。
Memory Cotroller
负责控制图形卡的内存访问。
GPC、TPC和SM
GPU包含若干GPC (Graphics Processing Cluster, 图形处理簇)组成的阵列。GPC又包含若干TPC (Texture Processing Cluster)。TPC中包含若干SM (Stream Multiprocessor,流多处理器)。SM中包含若干CUDA Core和Tensor Core。
L2 Cache
所有的 SM 共享 L2 缓存。可以通过缓存访问全局内存中的数据。
NVLink
NVLink 是一种GPU 之间的直接互连,双向互连速度达1.8 TB/s,可扩展服务器内的多GPU 输入/输出(IO)。实现多GPU通信。
High-Speed Hub
在GPU架构接口层面上,NVLink控制器通过另一个名为High-Speed Hub(HSHUB)的新块与GPU内部通信。HSHUB直接访问GPU宽交叉开关和其他系统元素,例如高速复制引擎(HSCE),可用于以最高NVLink速率将数据移动进入和移出GPU。
GigaThread Engine MIG Control
由PCIe接口进入的计算任务,通过带有多实例GPU(Multi-Instance GPU,MIG)控制的GigaThread引擎分配给各个GPC。GPC之间通过L2缓存共享中间数据,GPC计算的中间数据通过NVLink与其他GPU连接/交换。每个TPC由2个流式多处理器(Streaming Multiprocessor,SM)组成。
GPU的内部存储
GPU 内存可以分为:局部内存(local memory)、全局内存(global memory)、常量内存(constant memory)、共享内存(shared memory)、寄存器(register)、L1/L2 缓存等。其中全局内存、局部内存、常量内存都是片下内存,储存在 HBM 上。
全局内存
全局内存(global memory)能被 GPU 的所有线程访问,全局共享。它是片下(off chip)内存。跟 CPU 架构一样,运算单元不能直接使用全局内存的数据,需要经过缓存。
L1/L2缓存
L2 缓存可以被所有 SM 访问,速度比全局内存快;L1 缓存用于存储 SM 内的数据,被 SM 内的 CUDA cores 共享,但是跨 SM 之间的 L1 不能相互访问。
合理运用 L2 缓存能够提速运算。A100 的 L2 缓存能够设置至多 40MB 的持续化数据 (persistent data),能够拉升算子 kernel 的带宽和性能。Flash attention 的思路就是尽可能地利用 L2 缓存,减少 HBM 的数据读写时间。
局部内存
局部内存 (local memory) 是线程独享的内存资源,线程之间不可以相互访问。局部内存属于片下内存,所以访问速度跟全局内存一样。它主要是用来应对寄存器不足时的场景,即在线程申请的变量超过可用的寄存器大小时,nvcc 会自动将一部数据放置到片下内存里。
寄存器
寄存器(register)是线程能独立访问的资源,它是片上(on chip)存储,用来存储一些线程的暂存数据。寄存器的速度是访问中最快的,但是它的容量较小,只有几百甚至几十 KB,而且要被许多线程均分。
共享内存
共享内存(shared memory) 是一种在线程块内能访问的内存,是片上(on chip)存储,访问速度较快。
共享内存主要是缓存一些需要反复读写的数据。
注:共享内存与 L1 缓存的位置、速度极其类似,区别在于共享内存的控制与生命周期管理与 L1 不同:共享内存受用户控制,L1 受系统控制。共享内存更利于线程块之间数据交互。
常量内存
常量内存(constant memory)是片下(off chip)存储,但是通过特殊的常量内存缓存(constant cache)进行缓存读取,它是只读内存。
常量内存主要是解决一个 warp scheduler 内多个线程访问相同数据时速度太慢的问题。假设所有线程都需要访问一个 constant_A 的常量,在存储介质constant_A 的数据只保存了一份,而内存的物理读取方式决定了多个线程不能在同一时刻读取到该变量,所以会出现先后访问的问题,这样使得并行计算的线程出现了运算时差。常量内存正是解决这样的问题而设置的,它有对应的 cache 位置产生多个副本,让线程访问时不存在冲突,从而保证并行度。
流式处理器(SM)
进入SM单元的指令首先存入L1指令缓存(L1 Instruction Cache),然后再分发到L0指令缓存(L1 Instruction Cache)。与L0缓存配套的线程束排序器(Wrap Scheduler)和调度单元(Dispatch Unit)来为CUDA核心和张量核心分配计算任务。(注:GPU中最小的硬件计算执行单位是线程束,简称Warp。)
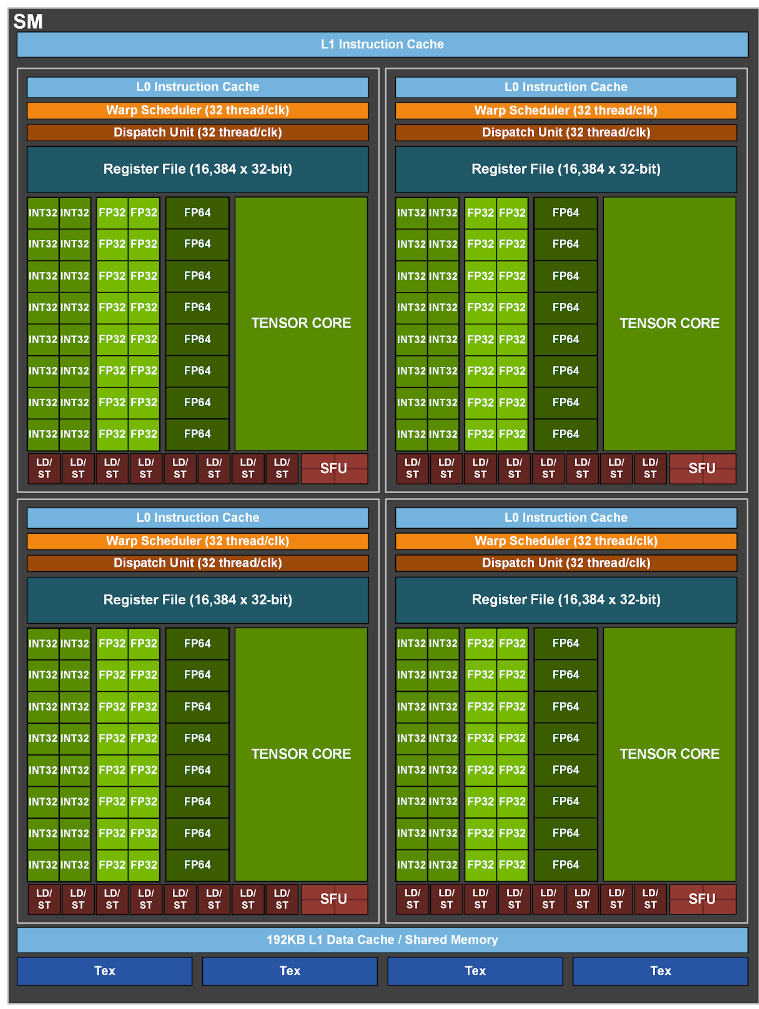
Warp Scheduler(线程调度器)
warp是GPU中最小的执行单元,由一组并行执行的线程组成,通常是32个线程。
Warp Scheduler负责选择哪个warp在下一个时钟周期内执行。它根据warp的状态(如是否有待执行的指令、是否有数据依赖等)来决定选择哪个warp。
每个SM通常配备多个warp调度器(如Volta架构中每个SM有4个warp调度器)。这些调度器能够并行调度多个warp,从而提高指令级并行性和吞吐量。
Dispatch Unit(调度单元)
Dispatch Unit从指令缓存中获取指令,并将这些指令分发给适当的执行单元(如整数运算单元、浮点运算单元、特殊功能单元等)。
Dispatch Unit负责从Warp Scheduler处接收准备好执行的warp,并将这些warp的指令分发给执行单元。Warp Scheduler管理多个warp的状态和调度,而Dispatch Unit具体执行这些warp的指令分发。
LD/ST(存储队列)
处理从各种内存层次(包括全局内存、共享内存和本地内存)进行的数据传输操作。
SFU(特殊计算单元)
用于运算超越函数(sin、cos、exp、log……)这是因为 3D 游戏中所有的立体形状其实都是由微小的三角形拼接而来,而显卡要计算的就是这些三角形的平移、旋转等等。
L1数据缓存
L1数据缓存主要用于缓存从全局内存中加载的数据,以加快数据访问速度。
它是硬件自动管理的缓存,程序员不需要显式地管理或控制。
Tex
在NVIDIA GPU的Streaming Multiprocessor (SM) 中,Tex单元(Texture Units)是负责处理纹理内存访问的关键组件。纹理单元用于加速特定类型的内存访问模式,特别是在计算机图形学和一些科学计算应用中非常有用。它们提供了高效的内存访问路径,并支持一些特殊功能,如纹理过滤和地址计算。
总结
每个 SM 包含 4 个 processing blocks,它们共用这个 SM 的 L1 Instruction Cache(一级指令缓存)、L1 Data Cache(一级数据缓存)、Tex(纹理缓存,Texture cache)
把大量这样的 SM 排布在一起,将它们连接在 L2 Cache 和全局的调度器(GigaThread Engine)上,再为整张芯片设置与外部通信的线路——这就是用于 Data Center 的安培架构显示核心 GA100 的所有组成成分。
CUDA软件编程
异构计算
异构
不同的计算机架构就是异构
CPU+GPU异构架构
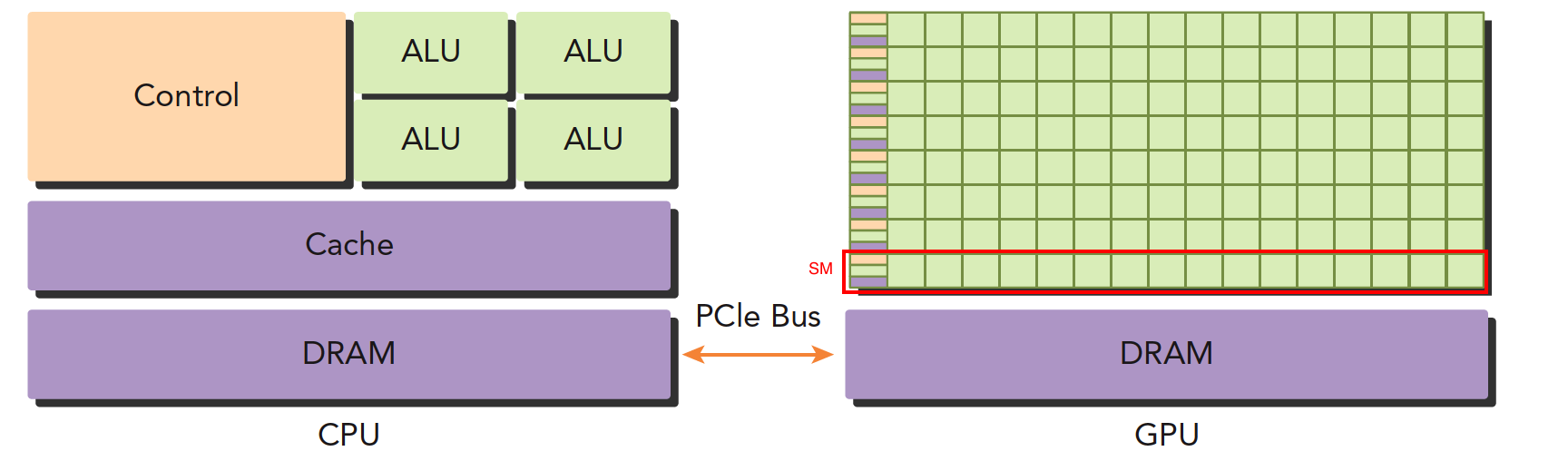
CPU负责控制,GPU负责计算
GPU计算指标
容量特征
CUDA核心数量(越多越好)
显存大小(越大越好)
性能指标
峰值计算能力:代表GPU的最大计算能力
显存带宽:显存与数据单元的通信速率
CPU和GPU线程区别
- CPU线程是重量级实体,操作系统交替执行线程,线程上下文切换花销很大
- GPU线程是轻量级的,GPU应用一般包含成千上万的线程,多数在排队状态,线程之间切换基本没有开销。
- CPU的核被设计用来尽可能减少一个或两个线程运行时间的延迟,而GPU核则是大量线程,最大幅度提高吞吐量
CUDA基本介绍
执行流程
CUDA nvcc编译器会自动分离代码里面的不同部分,如主机代码用C写成,使用本地的C语言编译器编译,设备端代码,也就是核函数,用CUDA C编写,通过nvcc编译,链接阶段,在内核程序调用或者明显的GPU设备操作时,添加运行时库。
CUDA的API接口
- CUDA驱动(driver)时API,相当于汇编语言,更加底层。
- 和CUDA驱动时(runtime)API
- 两者性能几乎无差异
编写程序流程
- 分配GPU内存
- 拷贝内存到设备
- 调用CUDA内核函数来执行计算
- 把计算完成数据拷贝回主机端
- 内存销毁
VS CUDA环境配置
cuda安装完成之后,打开VS,新建项目,选择CUDA xx.xx runtime。
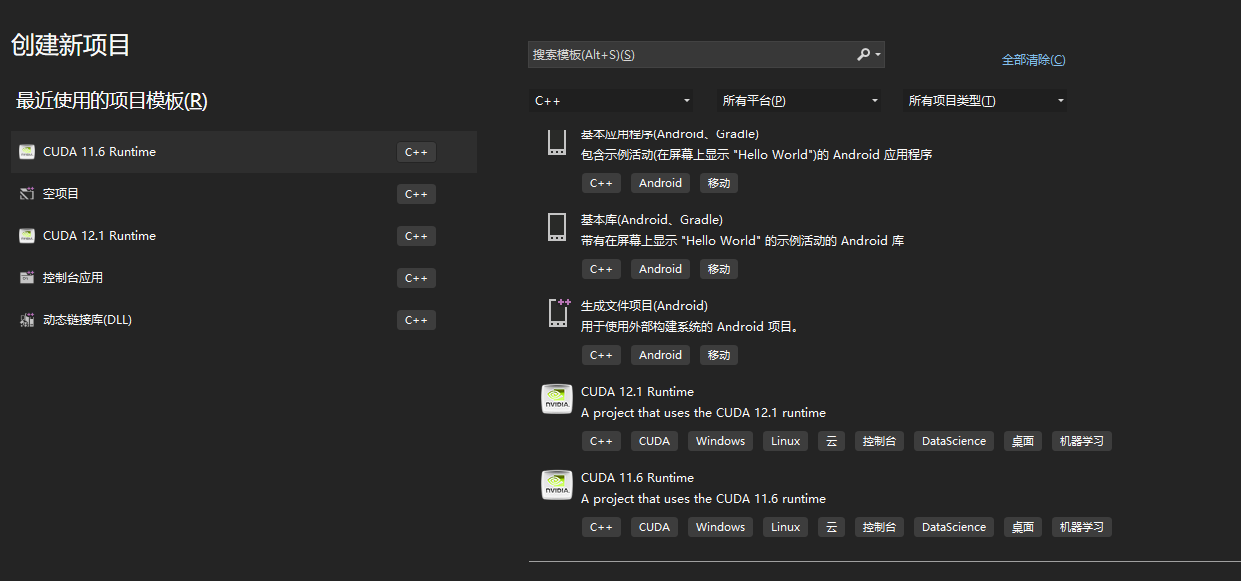
把.cu格式添加到编辑器和扩展名
(工具–>选项–>文本编辑器–>文件拓展名, 新增扩展名 .cu 并将编辑器设置为:Microsoft Visual C++。)
工具–>选项–>项目和解决方案–>VC++项目设置,添加要包括的扩展名”.cu”.)
示例——hello_world
1 | // 核函数hello_world |
注:cudaDeviceReset(); 这句话如果没有,则不能正常的运行,因为这句话包含了隐式同步,GPU和CPU执行程序是异步的,核函数调用后成立刻会到主机线程继续,而不管GPU端核函数是否执行完毕,所以上面的程序就是GPU刚开始执行,CPU已经退出程序了,所以我们要等GPU执行完了,再退出主机线程。
CUDA编程模型
CUDA的编程主要涉及到对GPU内存和线程的控制。
CUDA编程中的前缀
__host__ int foo(int a){}与C或者C++中的foo(int a){}相同,是由CPU调用,由CPU执行的函数__global__ int foo(int a){}表示一个内核函数,是一组由GPU执行的并行计算任务,以foo<<>>(a)的形式或者driver API的形式调用。目前__global__函数必须由CPU调用,并将并行计算任务发射到GPU的任务调用单元。随着GPU可编程能力的进一步提高,未来可能可以由GPU调用。__device__ int foo(int a){}则表示一个由GPU中一个线程调用的函数。由于Tesla架构的GPU允许线程调用函数,因此实际上是将__device__ 函数以__inline形式展开后直接编译到二进制代码中实现的,并不是真正的函数。
内存管理
cuda内存管理API
| 标准C函数 | CUDA C 函数 | 说明 |
|---|---|---|
| malloc | cudaMalloc | 内存分配 |
| memcpy | cudaMemcpy | 内存复制 |
| memset | cudaMemset | 内存设置 |
| free | cudaFree | 释放内存 |
线程管理
一个核函数只能有一个grid(网格),一个grid可以有很多block(块),一个块可以有很多thread(线程)。不同块内的线程是不能相互影响的,一个块内的线程是同步且共享内存的
在内核函数调用:
1 | kernel_func<<<M,N>>>; |
这里的kernel_func<<<M,N>>>表示语法调用了M个线程块(block),一个线程块中包含N个线程。这里的M和N除了整型变量,也可以是dim3变量,指定一个grid中的block数量和一个block中thread的数量。
线程标记
为了让线程彼此区分开,因此需要使用标记区分线程。注意区分两个概念:线程ID是独一无二的,线程索引指的是一个块内的线程的索引值,不同块内的索引值可能一样。
依靠下面两个基于uint3定义的内置结构体确定线程标号:
- blockIdx(线程块在线程网格内的位置索引)
- threadIdx(线程在线程块内的位置索引)
注:uint3是cuda的一个内置变量类型,继承自基本整形和浮点型,为结构体,包含3个成员x,y和z。其中u表示无符号数。**而且这里的Idx表示index的缩写,不是index x**。
使用:
- blockIdx.x
- blockIdx.y
- blockIdx.z
- threadIdx.x
- threadIdx.y
- threadIdx.z
我们要有同样对应的两个结构体来保存其范围,也就是blockIdx中三个字段的范围threadIdx中三个字段的范围:
- blockDim
- gridDim
注:在host,可以使用dim3定义grid和block的尺寸,作为kernel调用的一部分。dim3数据类型的手动定义的grid和block变量仅在host端可见。dim3是基于uint3的整数矢量类型。且未指定的组件都将初始化为。dim thread(3,4),创建了一个二位的34的dim3变量。在设备端访问grid和block属性的数据类型是uint3不能修改的常类型结构。*uint3是设备端在执行的时候可见的,不可以在核函数运行时修改,初始化完成后uint3值就不变了。
其使用过程如下:先用dim3类型指定grid和block,在核函数调用时,将kernel_func<<<grid block>>>,指定核函数调用时线程中一个网格中包括grid个块,一个块包含block个线程。线程布局如下图所示。

举个例子:假设你有一个网格,其中包含多个块,每个块包含多个线程。例如,如果你的blockDim为(8, 8, 1),这意味着每个块有64个线程,分布在8x8的网格中。如果你的blockIdx是(2, 3, 0),这意味着你正在引用网格中第三行第四列的块(索引从0开始)。最后,如果threadIdx是(4, 5, 0),则表示你正在指向块内第五行第六列的线程。
1 | dim3 block(3); // 定义一个block的dim3对象,并将block的x维度设为3,y和z的维度默认为1. |
注意:blockDim和gridDim只能在核函数中使用,在其余地方无法链接。
核函数
当主机启动了核函数,控制权马上回到主机,而不是主机等待设备完成核函数的运行。
如果核函数启动后的下一条指令就是从设备复制数据回主机端,那么主机端必须要等待设备端计算完成。
想要主机等待设备端执行可以用下面这个指令
1 | cudaError_t cudaDeviceSynchronize(void); |
核函数都是异步执行的
核函数编写限制
- 只能访问设备内存
- 必须有void返回类型
- 不支持可变数量的参数
- 不支持静态变量
- 显示异步行为
核函数开发流程
核函数一般将串行的程序变为并行的程序,首先编写好串行程序和并行程序(核函数),然后验证核函数,即分别执行核函数和串行函数,然后调用以下程序
1 | checkResult(res_cpu,res_gpu,nthread) |
CUDA小技巧,当我们进行调试的时候可以把核函数配置成单线程的
1 | kernel_name<<<1,1>>>(argument list) |
核函数计时
CPU计时
1 | clock_t start, finish; |
以上计时往往不准确,当需要获取准确的CPU计时,可参考如下程序
1 | // Windows下CPU精准计时方法 |
GPU计时
1 | cudaEvent_t start, stop; |
正常情况下,第一次执行核函数的时间会比第二次慢一些。这是因为GPU在第一次计算时需要warmup。所以想要第一次核函数的执行时间是不精确的。解决方法有以下两种:
- 在计时之前先执行一个warmup函数,warmup函数随便写。这种方法的优点是程序执行时间缩短;缺点是需要在程序中添加一个函数,而且因为GPU乱序并行的执行方式,核函数的两次执行时间并不能完全保持一样。
- 先执行warmup函数,在循环10遍计时部分。
组织并行线程
介绍每一个线程是怎么确定唯一的索引,然后建立并行计算,并且不同的线程组织形式是怎样影响性能的:
假如计算88的矩阵加法,使用二维网格(2,4),对应blockDim.x和blockDim.y和二维块(4,2),对应gridDim.x和gridDim.y一维网格(8)和一维块(8),二维网格(2,4)和一维块(8),为什么不指定一个核函数有几个块呢?因为*一个核函数只会对应一个块。
这里的块指块中线程维度,网格指网格中块的维度。
使用块和线程建立矩阵索引
首先区分局部地址(
threadIdx.x,threadIDx.y)和全局地址(ix,iy),其中
$$
ix = threadIdx.x + block.x \times blockDim.x \
iy = threadIdx.x + block.x \times blockDim.x
$$cuda的多线程中的多线程单指令是让每个不同的线程执行相同的代码但是处理的数据是不同的。CUDA常用的做法是让不同的线程对应不同的数据,也就是用线程的全局标号对应不同组的数据。线程索引如图所示。
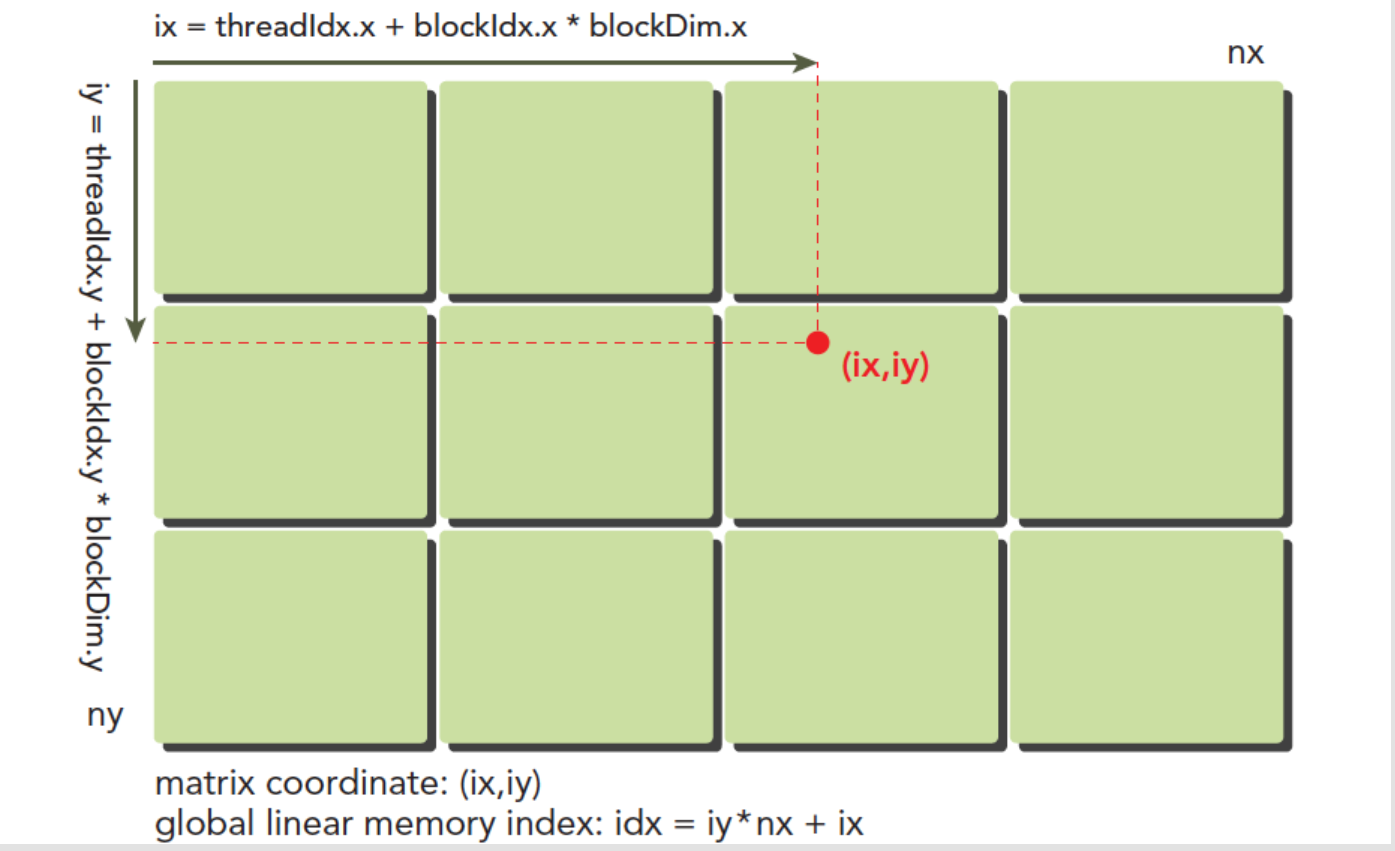
使用cuda实现二维矩阵加法
示例代码分析:
1 | __global__ void sumMatrix(float * MatA,float * MatB,float * MatC,int nx,int ny) |
CUDA执行模型
概述
SM
GPU中每个SM都能支持数百个线程并发执行,每个GPU通常有多个SM,当一个核函数的网格被启动的时候,多个block会被同时分配给可用的SM上执行。
当一个blcok被分配给一个SM后,他就只能在这个SM上执行了,不可能重新分配到其他SM上了,多个线程块可以被分配到同一个SM上。
线程束
到目前为止基本所有设备都是维持在一个线程束有32个线程,每个SM上有多个block,一个block有多个线程(可以是几百个,但不会超过某个最大值),机器的角度,在某时刻T,SM上只执行一个线程束,也就是32个线程在同时同步执行,线程束中的每个线程执行同一条指令,包括有分支的部分。
线程块里不同的线程可能进度都不一样,但是同一个线程束内的线程拥有相同的进度。
同一个SM上可以有不止一个常驻的线程束,有些在执行,有些在等待,他们之间状态的转换是不需要开销的。
SIMD vs SIMT
SIMD,单指令多数据,不允许每个分支有不同的操作,所有分支必须同时执行相同的指令,必须执行没有例外。
SIMT,单指令多线程,但是SIMT的某些线程可以选择不执行。一个SM在某一个时刻,有32个线程在执行同一条指令,这32个线程可以选择性执行,虽然有些可以不执行,但是他也不能执行别的指令,需要另外需要执行这条指令的线程执行完,然后再继续下一条。
- 每个线程都有自己的指令地址计数器
- 每个线程都有自己的寄存器状态
- 每个线程可以有一个独立的执行路径
线程束调度器
每个SM有n个线程束调度器,和两个指令调度单元,当一个线程块被指定给一个SM时,线程块内的所有线程被分成线程束,线程束选择其中n个线程束,在用指令调度器存储两个线程束要执行的指令,下图以每个SM中有两个线程束调度器为例,线程束调度器和指令调度单元的控制流程如下。
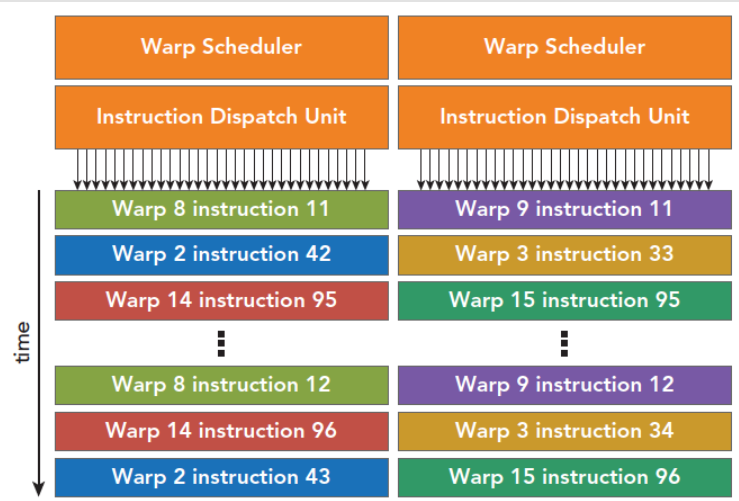
Hyper-Q技术
由于 GPU 核数较多, 抢占 GPU 需要保存大量的上下文信息, 开销较大, 所以目前市场上 GPU 都不支持抢占特性. 只用当前任务完成之后, GPU 才能被下个应用程序使用。 在 GPU 虚拟化的环境中, 多用户使用的场景会导致 GPU 进行频繁的任务切换, 可抢占的 GPU 能够防止恶意用户长期占用, 并且 能够实现用户优先级权限管理。
Hyper-Q:允许多个CPU 线程或进程同时加载任务到一个GPU上, 实现CUDA kernels的并发执行 –- 硬件特性
参考文章:GPU中的Hyper-Q技术 | 云里雾里 (damonyi.cc)
使用Profile进行优化
使用性能分析工具。
- nvvp
- nvprof
限制内核性能的主要包括但不限于以下因素
- 存储带宽
- 计算资源
- 指令和内存延迟
线程束执行的本质
线程束和线程块
当一个核函数执行时,可分为以下几个步骤:、
一个网格被启动(每个核函数对应一个网格),一个网格包含
gridDim.x * gridDim.y * gridDim.z个线程块。线程块被分配到SM中(一个block只能被分配到一个SM中,一个SM可以执行好几个block)。
分配到SM中后,线程块将被分为n个线程束,一个线程束包括32个线程(目前硬件规定的值),在一个线程束中,所有线程按照单指令多线程SIMT的方式执行,每一步执行相同的指令,但是处理的数据为私有的数据,也就是数据不同。当线程块中的线程数不能被32整除时,n向上取整。
当一个线程块中有128个线程的时候,其分配到SM上执行时,会分成4个块,按照线程编号将线程分配到线程束中:
1
2
3
4warp0: thread 0,........thread31
warp1: thread 32,........thread63
warp2: thread 64,........thread95
warp3: thread 96,........thread127
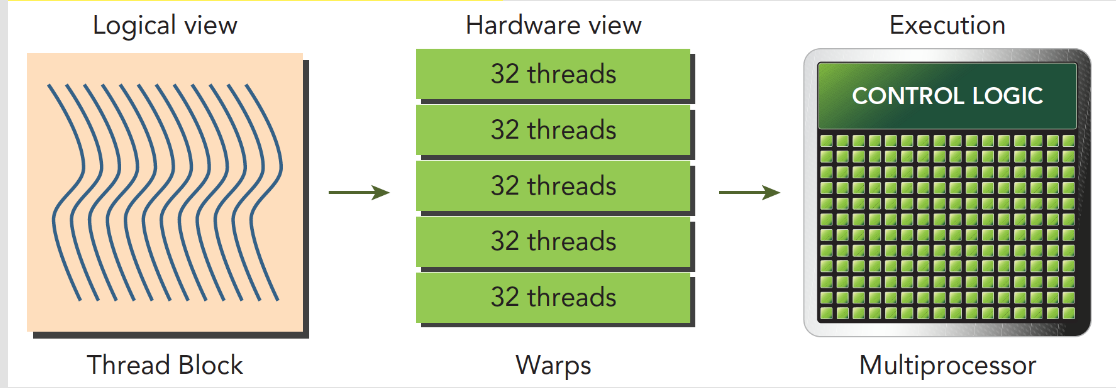
线程束和线程块,一个是硬件层面的线程集合,一个是逻辑层面的线程集合,我们编程时为了程序正确,必须从逻辑层面计算清楚,但是为了得到更快的程序,硬件层面是我们应该注意的。
补充:一个线程束中的threadIdx.x 是连续变化的
线程束分化
假设这段代码是核函数的一部分,那么当一个线程束的32个线程执行这段代码的时候,如果其中16个执行if中的代码段,而另外16个执行else中的代码块,同一个线程束中的线程,执行不同的指令,这叫做线程束的分化。
1 | if (con) |
线程束的分化会带来性能的削弱,因为分配命令的调度器就一个,两个分支就需要两个指令周期才能执行完。
优化方法:这就使得我们根据线程编号来设计分支是可以的,补充说明下,当一个线程束中所有的线程都执行if或者,都执行else时,不存在性能下降;只有当线程束内有分歧产生分支的时候,性能才会急剧下降。线程束内的线程是可以被我们控制的,那么我们就把都执行if的线程塞到一个线程束中,或者让一个线程束中的线程都执行if,另外线程都执行else的这种方式可以将效率提高很多。示例如下:
1 | __global__ void mathKernel2(float *c) |
注意warpSize这个常量值为32,可以使用这个优化程序。
资源分配
一个SM上被分配多少个线程块和线程束取决于SM中可用的寄存器和共享内存,以及内核需要的寄存器和共享内存大小。当kernel占用的资源较少,那么更多的线程(这是线程越多线程束也就越多)处于活跃状态,相反则线程越少。
特别是当SM内的资源没办法处理一个完整块,那么程序将无法启动。
当寄存器和共享内存分配给了线程块,这个线程块处于活跃状态,所包含的线程束称为活跃线程束。
活跃的线程束又分为三类:
- 选定的线程束
- 阻塞的线程束
- 符合条件的线程束
当SM要执行某个线程束的时候,执行的这个线程束叫做选定的线程束,准备要执行的叫符合条件的线程束,如果线程束不符合条件还没准备好就是阻塞的线程束。
满足下面的要求,线程束才算是符合条件的:
- 32个CUDA核心可以用于执行
- 执行所需要的资源全部就位
延迟隐藏
延迟隐藏,延迟是什么,就是当你让计算机帮你算一个东西的时候计算需要用的时间。延迟影藏就是通过添加任务优化让计算机的延迟缩小,原来的延迟和缩小后的延迟之差就是延迟隐藏。
所以最大化是要最大化硬件,尤其是计算部分的硬件满跑,都不闲着的情况下利用率是最高的,总有人闲着,利用率就会低很多,即最大化功能单元的利用率。利用率与常驻线程束直接相关。
硬件中线程调度器负责调度线程束调度,当每时每刻都有可用的线程束供其调度,这时候可以达到计算资源的完全利用,以此来保证通过其他常驻线程束中发布其他指令的,可以隐藏每个指令的延迟。
对于指令的延迟,通常分为两种:
- 算术指令
- 内存指令
算数指令延迟是一个算术操作从开始,到产生结果之间的时间,这个时间段内只有某些计算单元处于工作状态,而其他逻辑计算单元处于空闲。
内存指令延迟很好理解,当产生内存访问的时候,计算单元要等数据从内存拿到寄存器,这个周期是非常长的。
延迟:
- 算术延迟 10~20 个时钟周期
- 内存延迟 400~800 个时钟周期
那么至少需要多少线程,线程束来保证最小化延迟呢?
$$
所需线程束 = 延迟 \times 吞吐量
$$
吞吐量是指实际操作过程中每分钟处理多少个指令。
另外有两种方法可以提高并行:
- 指令级并行(ILP): 一个线程中有很多独立的指令
- 线程级并行(TLP): 很多并发地符合条件的线程
我们的根本目的是把计算资源,内存读取的带宽资源全部使用满,这样就能达到理论的最大效率。
那么我们怎么样确定一个线程束的下界呢,使得当高于这个数字时SM的延迟能充分的隐藏,其实这个公式很简单,也很好理解,就是SM的计算核心数乘以单条指令的延迟,
比如32个单精度浮点计算器,每次计算延迟20个时钟周期,那么我需要最少 32x20 =640 个线程使设备处于忙碌状态。
占用率
占用率是一个SM种活跃的线程束的数量,占SM最大支持线程束数量的比。
同步
同步的目的是为了避免内存竞争。
CUDA同步这里只讲两种:
- 线程块内同步
- 系统级别(
cudaDeviceSynchronize())
块级别的就是同一个块内的线程会同时停止在某个设定的位置,使用
1 | __syncthread(); |
这个函数只能同步同一个块内的线程,不能同步不同块内的线程,想要同步不同块内的线程,就只能让核函数执行完成,控制程序交换主机,这种方式来同步所有线程。
使用工具分析核函数执行效率
Visual Profiler 和 nvprof 将在未来的 CUDA 版本中被弃用。NVIDIA Volta 平台是完全支持这些工具的最后一个架构。建议使用下一代工具, NVIDIA Nsight Systems 用于 GPU 和 CPU 采样和跟踪,以及 NVIDIA Nsight Compute 用于 GPU 内核分析
Nsight Systems vs Nsight Compute
Nsight Systems:是用于系统级别性能分析和优化的工具,可以用于分析整个系统中的CPU、GPU和内存等资源的使用情况。用于调试和优化在复杂系统环境中运行的大型应用程序,尤其是需要同时关注多个硬件资源的情况。
Nsight Compute:Nsight Compute是一款专门针对GPU的内核级(kernel-level)分析工具。它用于深入分析和优化CUDA内核的性能。提供详细的GPU内核性能指标,包括内存带宽、指令吞吐量、线程效率等。可以查看和分析每个CUDA内核在不同硬件单元上的性能数据,如寄存器使用、缓存命中率等。自动识别CUDA内核中的性能瓶颈,并提供优化建议。用于CUDA开发人员对GPU内核进行精细调优,找到和解决特定的内核性能瓶颈。
Nsight Compute
原理: Nsight Compute将其测量库插入到应用程序进程中,从而允许分析器拦截与 CUDA 用户模式驱动程序的通信。此外,当检测到内核启动时,库可以从 GPU 收集请求的性能指标。然后将结果传输回前端。
避免分支化
普通优化
基本思想是利用线程编号,避免编号相近的线程被执行不同的指令,这样会造成线程束分化。
for循环优化
对于for循环,for循环也会造成线程束分化,因为下一次循环需要上一次计算结果的话,那么就会造成分化
改善for循环的分化方法是修改循环体的内容,让for循环的步长增加。
线程束最后32个线程优化
对于循环中线程束的最后32个线程,可以让不足32个线程的步骤,每一步跑满32个线程。
例如:
1 | volatile int *vmem = idata; |
注:因为我们的CUDA内核从内存中读数据到寄存器,然后进行加法都是同步进行的,也就是17号线程和1号线程同时读33号和17号的内存,这样17号即便在下一步修改,也不影响1号线程寄存器里面的值了。
volatile int类型变量是控制变量结果写回到内存,而不是存在共享内存,或者缓存中,因为下一步的计算马上要用到它,如果写入缓存,可能造成下一步的读取会读到错误的数据
id+16要用到tid+32的结果,会不会有其他的线程造成内存竞争,答案是不会的,因为一个线程束,执行的进度是完全相同的,当执行 tid+32的时候,这32个线程都在执行这步,而不会有任何本线程束内的线程会进行到下一句。
CUDA内存模型
概述
内存层次结构特点
内存速度从快到慢,内存大小从小到大:寄存器(Registers)、缓存(Caches)、内存(Main Memory)、硬盘(Disk Memory)
可编程内存VS不可编程内存:CPU内存中,一级二级缓存都是不可编程的存储设备。
CUDA的存储器可以大致分为两类:
- 板载显存(On-board memory)(DRAM)
- 片上内存(On-chip memory)
其中板载显存主要包括全局内存(global memory)、本地内存(local memory)、常量内存(constant memory)、纹理内存(texture memory)等,片上内存主要包括寄存器(register)和共享内存(shared memory)。
CUDA内存模型
GPU内存设备:寄存器、共享内存、本地内存、常量内存、纹理内存、全局内存。
区别:CUDA中每个线程都有自己的私有的本地内存;线程块有自己的共享内存,对线程块内所有线程可见;所有线程都能访问读取常量内存和纹理内存,但是不能写,因为他们是只读的;全局内存,常量内存和纹理内存空间有不同的用途。对于一个应用来说,全局内存,常量内存和纹理内存有相同的生命周期。
寄存器
CPU:只有当前在计算的变量存储在寄存器中,其余在主存中,使用时传输至寄存器。
GPU:当我们在核函数内不加修饰的声明一个变量,此变量就存储在寄存器中,在核函数中定义的有常数长度的数组也是在寄存器中分配地址的。如果一个线程里面的变量太多,以至于寄存器完全不够呢?这时候寄存器发生溢出,本地内存就会过来帮忙存储多出来的变量,这种情况会对效率产生非常负面的影响。
寄存器对于每个线程是私有的,寄存器通常保存被频繁使用的私有变量,注意这里的变量也一定不能使共有的,不然的话彼此之间不可见,就会导致大家同时改变一个变量而互相不知道。
为了避免寄存器溢出,可以在核函数的代码中配置额外的信息来辅助编译器优化,比如:
1 | __global__ void |
本地内存
函数中符合存储在寄存器中但不能进入被核函数分配的寄存器空间中的变量将存储在本地内存中,编译器可能存放在本地内存中的变量有以下几种:
- 使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地数组或者结构体
- 任何不满足核函数寄存器限定条件的变量
本地内存实质上是和全局内存一样在同一块存储区域当中的,其访问特点——高延迟,低带宽。
对于2.0以上的设备,本地内存存储在每个SM的一级缓存,或者设备的二级缓存上。
共享内存
修饰符:__share__。
特点:每个SM都有一定数量的由线程块分配的共享内存,共享内存是片上内存,跟主存相比,速度要快很多。
注意:不要因为过度使用共享内存,而导致SM上活跃的线程束减少,也就是说,一个线程块使用的共享内存过多,导致更过的线程块没办法被SM启动,这样影响活跃的线程束数量。
生命周期:线程块运行开始,此块的共享内存被分配,当此块结束,则共享内存被释放。取决于线程块。
如何避免内存竞争:使用同步语句:void __syncthreads();,但不要频繁使用,会影响内核执行效率。此语句相当于在线程块执行时各个线程的一个障碍点,当块内所有线程都执行到本障碍点的时候才能进行下一步的计算,这样可以设计出避免内存竞争的共享内存使用程序。
注:在硬件结构中,SM中的一级缓存,和共享内存共享一个片上内存,他们通过静态划分,划分彼此的容量,运行时可以通过下面语句进行设置:使用
1 | cudaError_t cudaFuncSetCacheConfig(const void * func,enum cudaFuncCache); |
常量内存
修饰符:__constant__
特点:量内存在核函数外,全局范围内声明,对于所有设备,只可以声明64k的常量内存,常量内存静态声明,并对同一编译单元中的所有核函数可见。被主机端初始化后不能被核函数修改,可以被主机端代码修改。
初始化:使用
1 | cudaError_t cudaMemcpyToSymbol(const void* symbol,const void *src,size_t count); |
当线程束中所有线程都从相同的地址取数据时,常量内存表现较好,比如执行某一个多项式计算,系数都存在常量内存里效率会非常高,但是如果不同的线程取不同地址的数据,常量内存就不那么好了,因为常量内存的读取机制是:一次读取会广播给所有线程束内的线程。
纹理内存
纹理内存在每个SM的只读缓存中缓存,只读缓存包括硬件滤波的支持,它可以将浮点插入作为读取过程中的一部分来执行,纹理内存是对二维空间局部性的优化。
全局内存
一般在主机端代码里定义,也可以在设备端定义,不过需要加修饰符,只要不销毁,是和应用程序同生命周期的。
静态声明:__device__
动态声明:cudaMalloc
注1:当有多个核函数同时执行的时候,如果使用到了同一全局变量,应注意内存竞争。
注2:全局内存访问是对齐,也就是一次要读取指定大小(32,64,128)整数倍字节的内存。
GPU缓存
与CPU缓存类似,GPU缓存不可编程,其行为出厂是时已经设定好了。GPU上有4种缓存:
- 一级缓存:每个SM都有一个一级缓存
- 二级缓存:所有SM公用一个二级缓存
- 只读常量缓存
- 只读纹理缓存
一级二级缓存的作用都是被用来存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。
每个SM有一个只读常量缓存,只读纹理缓存,它们用于设备内存中提高来自于各自内存空间内的读取性能。
静态全局内存
使用示例:
1 | __device float devData |
注1:cudaMemcpyToSymbol(devData,&value,sizeof(float));函数原型中使用void* symbol,这里为什么可以使用__device__ float devData。这是因为设备变量在代码中定义的时候其实就是一个指针,这个指针指向何处,主机端是不知道的,指向的内容也不知道,想知道指向的内容,唯一的办法还是通过显式的办法传输过来。
注2:不可以直接使用cudaMemcpy,这是动态复制方法,若要使用。需要首先使用cudaGetSymbolAddress((void**)&dptr,devData)获得设备变量地址。主机端是不可以直接对设备端的变量取地址的。
1 | float *dptr=NULL; |
内存管理
内存分配和释放
分配
1 | cudaError_t cudaMalloc(void **devPtr, size_t nByte); //第一个参数是指针的指针 |
初始化内存
1 | cudaError_t cudaMemset(void *devPtr,int value, size_t count); // 这一段内存的值都分配为value |
释放
1 | cudaError_t cudaFree(void *devPtr) |
内存传输
传输
1 | cudaError_t cudaMemcpy(void *dst,const void * src,size_t count,enum cudaMemcpyKind kind) |
传输类型
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
CPU和GPU之间通信要经过PCIe总线,总线的理论峰值要低很多——8GB/s左右,也就是说所,管理不当,算到半路需要从主机读数据,那效率瞬间全挂在PCIe上了。CUDA编程需要大家减少主机和设备之间的内存传输。
固定内存
主机内存采用分页式管理,通俗的说法就是操作系统把物理内存分成一些“页”,然后给一个应用程序一大块内存,但是这一大块内存可能在一些不连续的页上,应用只能看到虚拟的内存地址,而操作系统可能随时更换物理地址的页(从原始地址复制到另一个地址)但是应用是不会觉得,但是从主机传输到设备上的时候,如果此时发生了页面移动,对于传输操作来说是致命的。
因此CUDA传输内存时通过两种方式解决:
- 正常分配内存:锁页-复制到固定内存-复制到设备
- 固定内存:直接分配固定的主机内存,将主机源数据复制到固定内存上,然后从固定内存传输数据到设备上
分配固定内存,这样就是的传输带宽变得高很多
1 | cudaError_t cudaMallocHost(void ** devPtr,size_t count) |
固定的主机内存释放
1 | cudaError_t cudaFreeHost(void *ptr) |
固定内存的释放和分配成本比可分页内存要高很多,但是传输速度更快,所以对于大规模数据,固定内存效率更高。尽量使用流来使内存传输和计算之间同时进行。
零拷贝内存
GPU线程可以直接访问零拷贝内存,这部分内存在主机内存里面,因此零拷贝内存是实现了设备访问主机内存。
CUDA核函数使用零拷贝内存有以下几种情况:
- 当设备内存不足的时候可以利用主机内存
- 避免主机和设备之间的显式内存传输
- 提高PCIe传输率
零拷贝内存是固定内存,不可分页。
创建零拷贝内存
1 | cudaError_t cudaHostAlloc(void ** pHost,size_t count,unsigned int flags) |
标志参数可选值
- cudaHostAllocDefalt:等同于
cudaMallocHost,分配主机内存 - cudaHostAllocPortable:返回能被所有CUDA上下文使用的固定内存
- cudaHostAllocWriteCombined:返回写结合内存,在某些设备上这种内存传输效率更高
- cudaHostAllocMapped:产生零拷贝内存
创建完成之后设备还是不能通过phost指针来访问对应的主机内存地址,需要先获得另一个地址
1 | cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags); |
pDevice就是设备上访问主机零拷贝内存的指针,此处flag必须设置为0。
零拷贝内存可以当做比设备主存储器更慢的一个设备。
统一虚拟寻址(UVA)
设备内存和主机内存被映射到同一虚拟内存地址中。
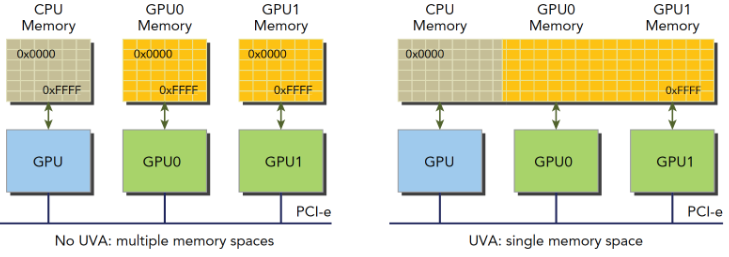
通过UVA,cudaHostAlloc函数分配的固定主机内存具有相同的主机和设备地址,可以直接将返回的地址传递给核函数。也就是说不需要上面的那个获得设备上访问零拷贝内存的函数了。(cudaError_t cudaHostGetDevicePointer(void ** pDevice,void * pHost,unsigned flags))
统一内存寻址
统一内存中创建一个托管内存池(CPU上有,GPU上也有),内存池中已分配的空间可以通过相同的指针直接被CPU和GPU访问,底层系统在统一的内存空间中自动的进行设备和主机间的传输。
托管内存是指底层系统自动分配的统一内存,未托管内存就是我们自己分配的内存,这时候对于核函数,可以传递给他两种类型的内存,已托管和未托管内存,可以同时传递。
托管内存可以是静态的,也可以是动态的,添加 managed关键字修饰托管内存变量。静态声明的托管内存作用域是文件,这一点可以注意一下。
托管内存分配:
1 | cudaError_t cudaMallocManaged(void ** devPtr,size_t size,unsigned int flags=0) |
内存访问模式——全局内存
CUDA内存访问也是以线程束为基本单位发布和执行的,存储也一致。以下从线程束的内存访问进行描述:
核函数运行时需要从全局内存(DRAM)中读取数据,只有两种粒度(最小单位),也被称为缓存粒度
- 128字节
- 32字节
核函数运行时每次读内存,哪怕是读一个字节的变量,也要读128字节,或者32字节,而具体是到底是32还是128还是要看访问方式。
CUDA是支持通过编译指令停用一级缓存的。如果启用一级缓存,那么每次从DRAM上加载数据的粒度是128字节,如果不适用一级缓存,只是用二级缓存,那么粒度是32字节。
原因:L1缓存会预取更多的数据,因为相对于L2缓存,它离执行单元更近,缓存命中率更高,能更好地利用较大的加载粒度。此外,由于L1缓存更贴近线程执行,预取较大数据块可以减少未来访问时的延迟。
原因:当一个SM中正在被执行的某个线程需要访问内存,那么,和它同线程束的其他31个线程也要访问内存,这个基础就表示,即使每个线程只访问一个字节,那么在执行的时候,只要有内存请求,至少是32个字节,所以不使用一级缓存的内存加载(每个SM内部的L1缓存),一次粒度是32字节而不是更小。
对齐和合并访问
内存事务:从内核函数发起请求,到硬件响应返回数据这个过程。
对齐内存访问:当一个内存事务的首个访问地址是缓存粒度(32或128字节)的整数倍的时候。非对齐访问会造成内存浪费。
合并访问:当一个线程束内的线程访问的内存都在一个内存块里的时候,并且是对齐的,这些访问可以被合并为一个内存事务。为了提高内存访问效率,GPU尝试将一个Warp中的多个线程的内存访问请求合并为一个或几个内存事务。这意味着,如果一个Warp的32个线程访问的内存地址是连续的且对齐良好,GPU可以通过一次内存事务将所有数据加载到缓存或寄存器中。
对齐合并访问的状态是理想化的,也是最高速的访问方式,为了最大化全局内存访问的理想状态,尽量将线程束访问内存组织成对齐合并的方式,这样的效率是最高的。
优化关键:用最少的事务次数满足最多的内存请求。事务数量和吞吐量的需求随设备的计算能力变化。
全局内存读取
SM加载数据,根据不同的设备和类型分为三种路径:
一级和二级缓存
常量缓存
只读缓存
编译器禁用一级缓存
1 | -Xptxas -dlcm=cg |
编译器启用一级缓存
1 | -Xptxas -dlcm=ca |
当一级缓存被禁用的时候,对全局内存的加载请求直接进入二级缓存,如果二级缓存缺失,则由DRAM完成请求。
只读缓存:只读缓存最初是留给纹理内存加载用的,在3.5以上的设备,只读缓存也支持使用全局内存加载代替一级缓存。也就是说3.5以后的设备,可以通过只读缓存从全局内存中读数据了。只读缓存粒度32字节,对于分散读取,细粒度优于一级缓存。
从只读缓存中读取:
- 使用函数_ldg
- 在在间接引用的指针上使用修饰符
1 | out[idx] = _ldg(&in[idx]); |
全局内存写入
一级缓存不能用在 Fermi 和 Kepler GPU上进行存储操作,发送到设备前,只经过二级缓存,存储操作在32个字节的粒度上执行。
结构体数组与数组结构体
结构体在内存中的表现
结构中的成员在内存里对齐的依次排开
数组结构体(AOS)
一个数组,每个元素都是结构体
结构体数组(SOA)
结构体的成员都是数组
注1:CUDA对细粒度数组是非常友好的,但是对粗粒度如结构体组成的数组就不太友好,会导致内存访问利用率低。因为在访问某个结构体成员时,当32个线程同时访问时,AOS是不连续的,SOA是连续的,因此CUDA对SOA更友好。
共享内存
几个内存之间的关系
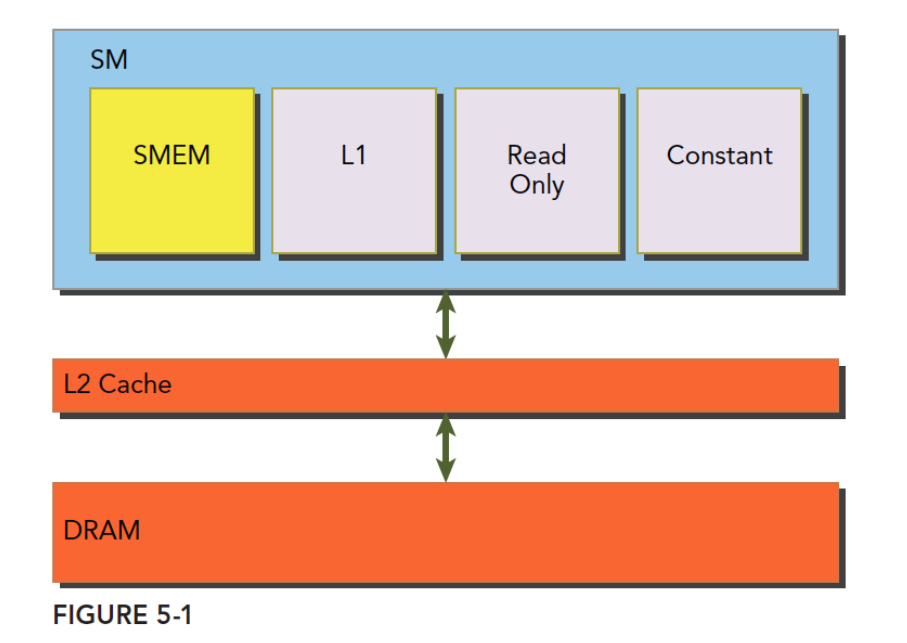
生存周期:共享内存是在他所属的线程块被执行时建立,线程块执行完毕后共享内存释放,线程块和他的共享内存有相同的生命周期。
共享内存越大,或者块使用的共享内存越小,那么线程块级别的并行度就越高。
内存分配
关键字
1 | __share__ float value; //声明共享内存变量 |
声明共享内存数组
1 | __share__ float MyArrary[x][y]; //声明二维数组 |
这里的x和y和C++声明数组一样,不能是变量,在编译的时候要是一个确定值。
共享内存的声明可以在核函数内,也可以在核函数外。
共享内存动态数组声明,使用extern关键字
1 | extern __share__ float value[]; //动态数组声明 |
访问模式
内存存储体
共享内存有个特殊的形式是,分为32个同样大小的内存模型(对应32个线程),称为存储体,可以同时访问。如果32个线程同时访问32个不同的存储体,则不会产生冲突。
存储体冲突
当多个线程要访问一个存储体的时候,冲突就发生了,注意这里是说访问同一个存储体,而不是同一个地址,访问同一个地址不存在冲突(广播形式)。
广播访问是所有线程访问一个地址,这时候,一个内存事务执行完毕后,一个线程得到了这个地址的数据,他会通过广播的形式告诉其他所有线程,虽然这个延迟相比于完全的并行访问并不慢,但是他只读取了一个数据,带宽利用率很差。
共享内存的存储体的访问模式
根据存储体的宽度(计算能力2.x的宽度为4字节,计算能力3.x的宽度为8字节),假如有1024字节的数据,存储体宽度为8字节,存储的时候,第一个8字节数据被放在第一个存储体,第二个8字节数据被放在第二个存储体,以此类推。等到32个存储体存完一遍后,再从第一个开始存储。
存储体索引
$$
存储体索引 = \frac{字节地址 ÷ 存储体宽度}{存储体数} \quad \bmod 存储体数
$$
如何解决存储体冲突——内存填充
假设存储体大小是5个(实际上是32个),当分配内存时声明,此时刚好填满
1 | __share__ int a[5][5] |

假如这时候访问bank 0的时候会有5线程的冲突,为了解决这个冲突,可以声明为
1 | __share__ int a[5][6] |
这样会在编程的时候加入一行填充物,然后编译器就会将二维数组重新分配内存,可以让所有元素都错开,如图所示。
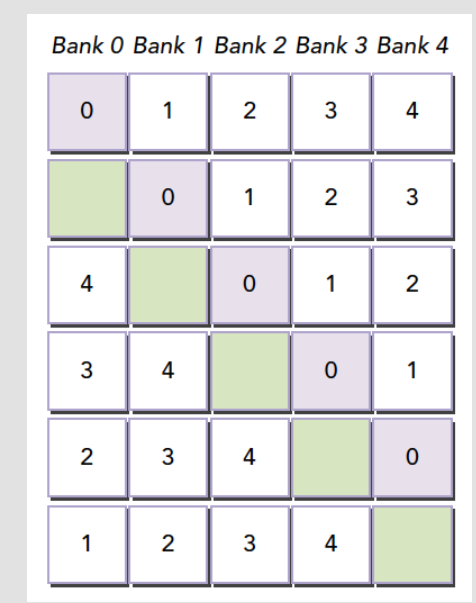
访问模式查询:4字节 or 8字节
1 | cudaError_t cudaDeviceGetSharedMemConfig(cudaSharedMemConfig * pConfig); |
返回pConfig的值
1 | cudaSharedMemBankSizeFourByte |
配置存储体大小
1 | cudaError_t cudaDeviceSetShareMemConfig(cudaSharedMemConfig config); |
config的值
1 | cudaSharedMemBankSizeDefault |
配置共享内存
每个SM上有64KB的片上内存,共享内存和L1共享这64KB,并且可以配置。此内存更多给核函数使用,多配置共享内存,给更多寄存器使用,多配置L1缓存。一级缓存和共享内存都在同一个片上,但是行为大不相同,共享内存靠的的是存储体来管理数据,而L1则是通过缓存行进行访问。我们对共享内存有绝对的控制权,但是L1的删除工作是硬件完成的。
配置函数
1 | cudaError_t cudaDeviceSetCacheConfig(cudaFuncCache cacheConfig); |
配置参数cacheConfig
1 | cudaFuncCachePreferNone: no preference(default) |
通过不同核函数自动配置共享内存
1 | cudaError_t cudaFuncSetCacheConfig(const void* func,enum cudaFuncCacheca cheConfig); |
这里的func是核函数指针,当我们调用某个核函数时,次核函数已经配置了对应的L1和共享内存,那么其如果和当前配置不同,则会重新配置,否则直接执行。
同步
同步基本方法
- 障碍:所有调用线程等待其余调用线程达到障碍点。
- 内存栅栏:所有调用线程必须等到全部内存修改对其余线程可见时才继续进行。
弱排序内存
CUDA采用宽松的内存模型,也就是内存访问不一定按照他们在程序中出现的位置进行的。宽松的内存模型,导致了更激进的编译器。核函数内连续两个内存访问指令,如果独立,其不一定哪个先被执行。
显示障碍
1 | void __syncthreads(); |
内存栅栏
内存栅栏能保证栅栏前的内核内存写操作对栅栏后的其他线程都是可见的,有以下三种栅栏:块,网格,系统。
线程块内:保证同一块中的其他线程对于栅栏前的内存写操作可见
1 | void __threadfence_block(); |
网格级内存栅栏:挂起调用线程,直到全局内存中所有写操作对相同的网格内的所有线程可见
1 | void __threadfence(); |
系统级栅栏:挂起调用线程,以保证该线程对全局内存,锁页主机内存和其他设备内存中的所有写操作对全部设备中的线程和主机线程可见。跨系统,包括主机和设备。
1 | void __threadfence_system(); |
Volatile修饰符:olatile声明一个变量,防止编译器优化,防止这个变量存入缓存,始终存放于全局内存中。
行主序和列主序
访问
当我们使用二维块的时候,可能会使用下列方式索引二维数组的数据
1
2
3__shared__ int x[N][N];
...
int a=X[thread.x][thread.y];由于共享内存按存储体进行存储,以
N=32为例。这样访问就可能导致冲突最大化。如下图所示: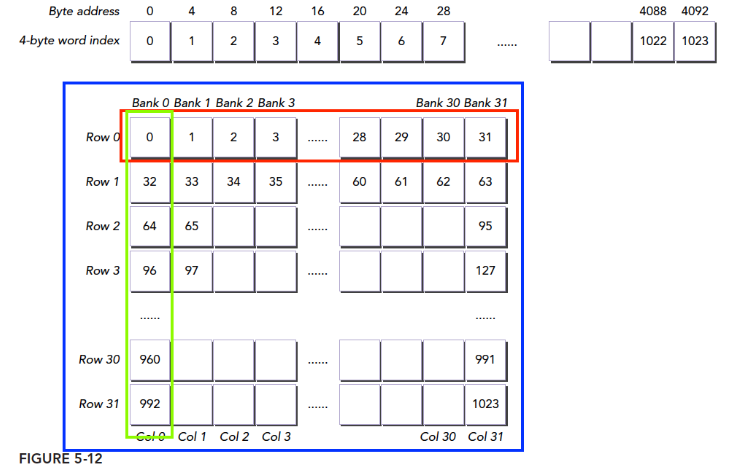
我们的数据是按照行放进存储体中的这是固定的,所以我们希望,这个线程束中取数据是按照行来进行的,所以
1
int a=X[thread.y][thread.x];
常量内存
读写权限: 对于内核代码是只读的,对于主机端是可读写的。
位置:DRAM,但在片上有对应的缓存。
最佳访问模式:线程束所有线程访问一个位置。
声明方式:
1 | __constant 常量内存名 |
生存周期:与应用程序生存周期相同,这就说明,所有网格(grid)对声明的常量内存都是可以访问的。运行时对主机可见,当CUDA独立编译被使用的,常量内存跨文件可见。
初始化常量内存:
1 | cudaError_t cudaMemcpyToSymbol(const void *symbol, const void * src, size_t count, size_t offset, cudaMemcpyKind kind) |
用法类似cudaMemcpy(d_a, h_a, nByte, cudaMemcpyHostToDevice)
只读缓存
特点:,只读缓存拥有从全局内存读取数据的专用带宽,所以,如果内核函数是带宽限制型的,那么这个帮助是非常大的,不同的设备有不同的只读缓存大小,Kepler SM有48KB的只读缓存,只读缓存对于分散访问的更好,当所有线程读取同一地址的时候常量缓存最好,只读缓存这时候效果并不好,只读换粗粒度为32。
使用方法:
使用
__leg函数1
2
3
4
5__global__ void kernel(float* output, float* input) {
...
output[idx] += __ldg(&input[idx]);
...
}使用限定指针
1
2
3
4void kernel(float* output, const float* __restrict__ input) {
...
output[idx] += input[idx];
}
应用场景:常量缓存喜欢小数据,而只读内存加载的数据比较大。
线程束洗牌指令
基本介绍
洗牌指令作用在线程束内,允许两个线程互相访问对方的寄存器,线程束内线程相互访问数据不通过共享内存或者全局内存,使得通信效率高很多,线程束洗牌指令传递数据,延迟极低,切不消耗内存。
束内线程(Lane)
就是一个线程束内的索引,所以束内线程的ID在 【0,31】【0,31】 内,且唯一,唯一是指线程束内唯一。
线程束洗牌指令的不同形式
线程束内交换变量(整型和浮点型)
1 | int __shfl(int var,int srcLane,int width=warpSize); |
- var:返回的线程的
var这个变量的值,对应的线程为srcLane - srcLane:
srcLane不是当前线程的束内线程,需要结合width算出来的相对线程。如我想得到3号线程内存的var值,而且width=16,那么就是,015的束内线程接收0+3位置处的var值,也就是3号束内线程的var值,1632的束内线程接收16+3=19位置处的var变量。
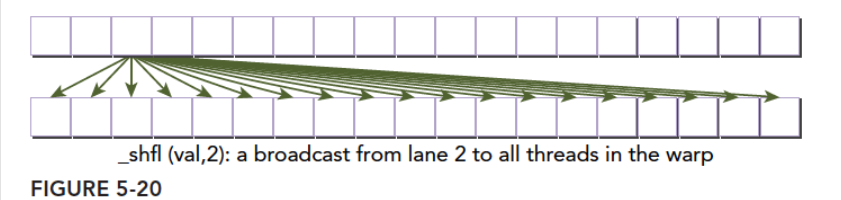
从与调用线程相关的线程中复制数据
1 | int __shfl_up(int var,unsigned int delta,int with=warpSize); |
作用:调用线程得到当前束内线程编号减去delta的编号的线程内的var值。
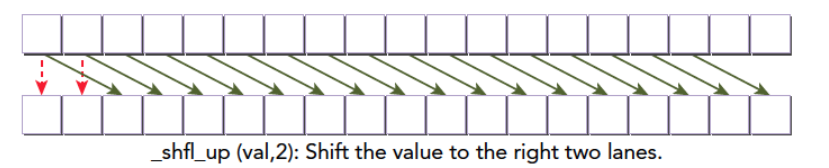
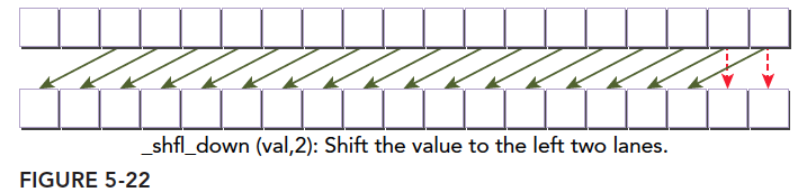
1 | int __shfl_down(int var,unsigned int delta,int with=warpSize); |
作用:调用线程得到当前束内线程编号加上delta的编号的线程内的var值。
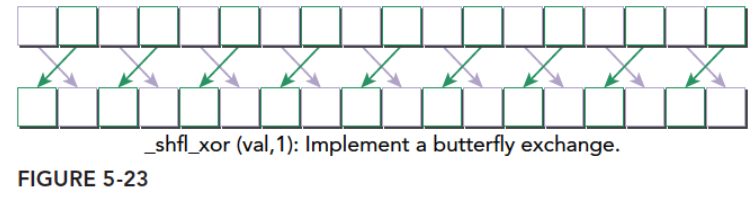
异或线程数据
1 | int __shfl_xor(int var,int laneMask,int with=warpSize); |
作用:如果我们输入的laneMask是1,其对应的二进制是 000⋯001000⋯001 ,当前线程的索引是0~31之间的一个数,那么我们用laneMask与当前线程索引(操作当前线程索引的var值)进行抑或操作得到的就是目标线程的编号了。
注意:shfl中计算目标线程编号的那步有取余操作,对with取余,我们真正得到的数据来自
1 | srcLane=srcLane%width; |
流和并发
和线程这个概念不同,流的概念主要是从主机的角度取理解同步和异步的。
并发和并行
并发:一个处理器同时处理多个任务。在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。是互相抢占资源的
并行:多个处理器或者多核的处理器同时处理多个任务。系统有一个以上CPU时,当一个CPU执行一个进程时,另一个CPU可以执行另一个进程,两个进程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。 这里面有一个很重要的点,那就是系统要有多个CPU才会出现并行。在有多个CPU的情况下,才会出现真正意义上的同时进行。不会出现互相抢占资源的情况。
同步和异步
同步:两个事物相互依赖,并且一个事物必须以依赖于另一事物的执行结果。比如在事物 A->B 事件模型中,你需要先完成事物 A 才能执行事物 B。也就是说,同步调用在被调用者未处理完请求之前,调用不返回,调用者会一直等待结果的返回。 同步请求就是要等待返回结果。
异步:两个事物完全独立,一个事物的执行不需要等待另外一个事物的执行。也就是说,异步调用可以返回结果不需要等待结果返回,当结果返回的时候通过回调函数或者其他方式带着调用结果再做相关事情。异步请求的时候不需要等待返回结果就去执行其他任务。
阻塞和非阻塞
阻塞:简单来说就是发出一个请求不能立刻返回响应,要等所有的逻辑全处理完才能返回响应。
非阻塞:发出一个请求立刻返回应答,不用等处理完所有逻辑。
阻塞与非阻塞指的是单个线程内遇到同步等待时,是否在原地不做任何操作。结合同步和异步,有以下几种分类。
- 同步阻塞 只有一个车道,不能超车,所有车子依次行使,一次只能通过一辆车,尴尬的是这个车道还堵车了。
- 同步非阻塞 只有一个车道,不能超车,所有车子依次行使,一次只能通过一辆车,不过比较幸运这个车道没有堵车,可以正常通行。
- 异步阻塞 有两个或两个以上车道,每条马路都可以通行,不同车道上的车子可以并行行使,尴尬的是所有的车道都堵车了。
- 异步非阻塞 有两个或两个以上车道,每条马路都可以通行,不同车道上的车子可以并行行使,不过比较幸运的是没有一个车道堵车,都可以正常通行。
CUDA 流(Stream)
CUDA 流相当于把一系列CUDA操作封装起来。
一个 CUDA 流指的是由主机发出的在一个设备中执行的 CUDA 操作序列。除主机端发出的流之外,还有设备端发出的流。
以下主要讨论主机发出的流,一个 CUDA 流中的各个操作按照主机发布的次序执行;但来自两个不同 CUDA 流的操作不一定按照某个次序执行,有可能是并发或者交错地执行。流能封装异步操作,并保持操作顺序,允许操作在流中排队。保证其在前面所有操作启动之后启动。
任何 CUDA 操作都存在于某个 CUDA 流中,如果没有明确指定 CUDA 流,那么所有 CUDA 操作都是在默认流中执行的。非默认 CUDA 流由cudaStream_t类型的变量表示。
为了产生多个相互独立的 CUDA 流、实现不同 CUDA 流之间的并发,主机在向某个 CUDA 流中发布命令后必须马上获取程序控制权,不等待该 CUDA 流中的命令在设备中执行完毕。
默认流
属于隐式声明的流,也被叫做空流,是同步的。
在 CUDA 中,所有的设备操作都在流(stream)中执行。当没有指定流时,使用默认的流。
比如我们常见的套路,在主机端分配设备主存(cudaMalloc),主机向设备传输数据(cudaMemcpy),核函数启动,复制数据回主机(Memcpy),就属于默认的流。默认流是一个针对设备操作同步的流,也就是说,只有当所有之前设备上任何流里面的操作全部完成时,才开始默认流里面操作的执行,并且默认流里面的一个操作必须完成,其他任何流里面的操作才能开始。
1 | cudaMemcpy(d_a, a, numBytes, cudaMemcpyHostToDevice); |
从设备端来看,这三个操作都在默认流中,并且按顺序执行;第一步主机到设备的数据传输是同步的,CPU线程不能到达第二行直到主机到设备的数据传输完成。 kernel 是异步的,即主机发出调用核函数的命令后,不会等待命令执行完毕,而会立刻取得程序控制权,然后紧接着发出最后一个cudaMemcpy命令,CPU线程移到第三行但是该命令不会立即被执行,因为这是默认流中的CUDA操作,必须等待前一个CUDA操作(即核函数的调用)执行完毕才会开始执行。
非默认流
属于显式声明的流,也被叫做非空流,是异步的。
非默认流的创建和销毁
1 | cudaError_t cudaStreamCreate(cudaStream_t* pStream); |
对于回收函数,由于流和主机端是异步的,你在使用上面指令回收流的资源的时候,很有可能流还在执行,这时候,这条指令会正常执行,但是不会立刻停止流,而是等待流执行完成后,立刻回收该流中的资源。这样做是合理的也是安全的。
检查流的操作是否在设备中完成
1 | //阻塞主机直到stream中的所有操作都执行完毕 |
异步的数据传输
意味着数据传输指令执行之后,控制权会立刻交给主机,不需要等待数据传输指令执行完毕。
1 | cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count,cudaMemcpyKind kind, cudaStream_t stream = 0); |
执行异步数据传输时,主机端的内存必须是固定的,非分页的!
在非空流中执行内核需要在启动核函数的时候加入一个附加的启动配置:
1 | kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list); |
pStream参数就是附加的参数,使用目标流的名字作为参数,比如想把核函数加入到a流中,那么这个stream就变成a。
举个栗子:
1 | for (int i = 0; i < nStreams; i++) { |
第一个for中循环执行了nStreams个流,每个流中都是“复制数据,执行核函数,最后将结果复制回主机”这一系列操作。
下面的图就是一个简单的时间轴示意图,假设nStreams=3,所有传输和核启动都是并发的:
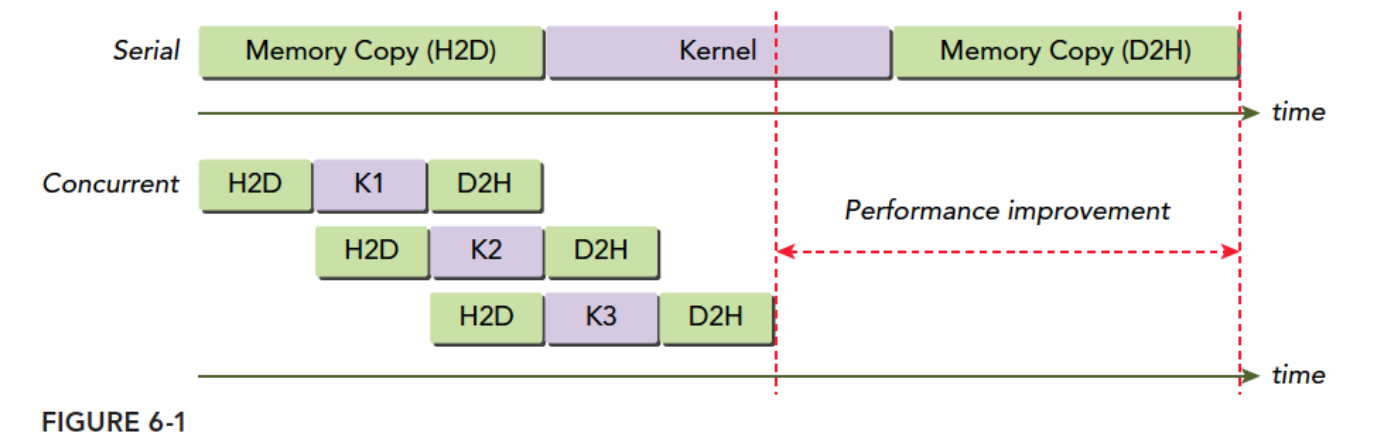
H2D是主机到设备的内存传输,D2H是设备到主机的内存传输。显然这些操作没有并发执行,而是错开的,原因是PCIe总线是共享的,当第一个流占据了主线,后来的就一定要等待,等待主线空闲。编程模型和硬件的实际执行时有差距了。
上面同时从主机到设备涉及硬件竞争要等待,如果是从主机到设备和从设备到主机同时发生,这时候不会产生等待,而是同时进行。
流调度
从编程模型看,所有流可以同时执行,但是硬件毕竟有限,不可能像理想情况下的所有流都有硬件可以使用,所以硬件上如何调度这些流是我们理解流并发的关键。
虚假的依赖关系
Fermi架构上16路流并发执行但是所有流最终都是在单一硬件上执行的,Fermi只有一个硬件工作队列,所以他们虽然在编程模型上式并行的,但是在硬件执行过程中是在一个队列中(像串行一样)。要执行某个网格的时候CUDA会检测任务依赖关系,如果其依赖于其他结果,那么要等结果出来后才能继续执行。单一流水线可能会导致虚假依赖关系:
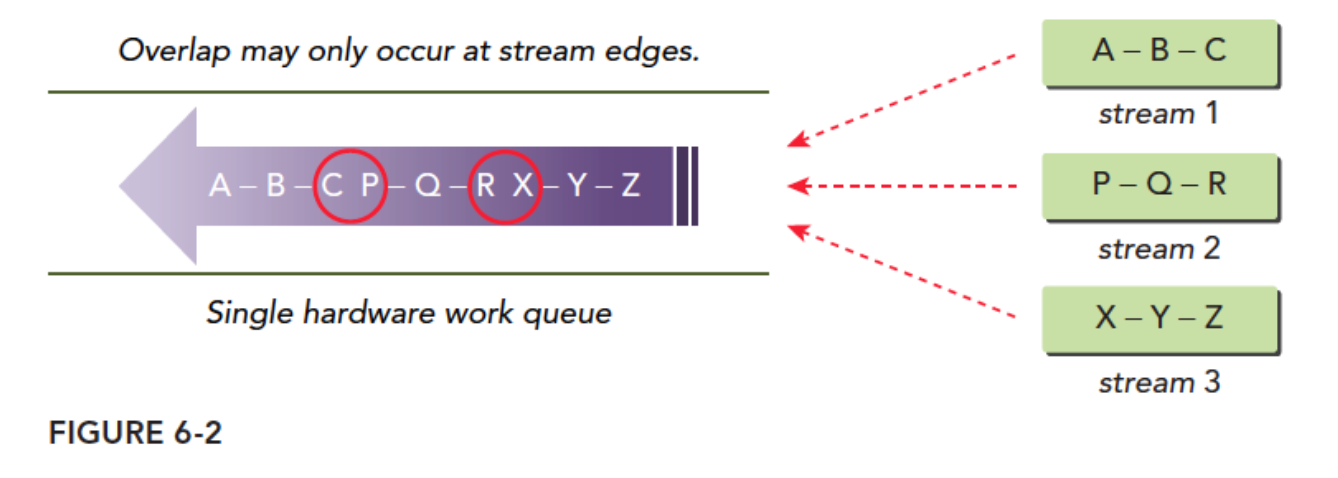
- 执行A,同时检查B是否有依赖关系,当然此时B依赖于A而A没执行完,所以整个队列阻塞
- A执行完成后执行B,同时检查C,发现依赖,等待
- B执行完后,执行C同时检查,发现P没有依赖,如果此时硬件有多于资源P开始执行
- P执行时检查Q,发现Q依赖P,所以等待
种一个队列的模式,会产生一种,虽然P依赖B的感觉,虽然不依赖,但是B不执行完,P没办法执行,而所谓并行,只有一个依赖链的头和尾有可能并行,也就是红圈中任务可能并行,而我们的编程模型中设想的并不是这样的。
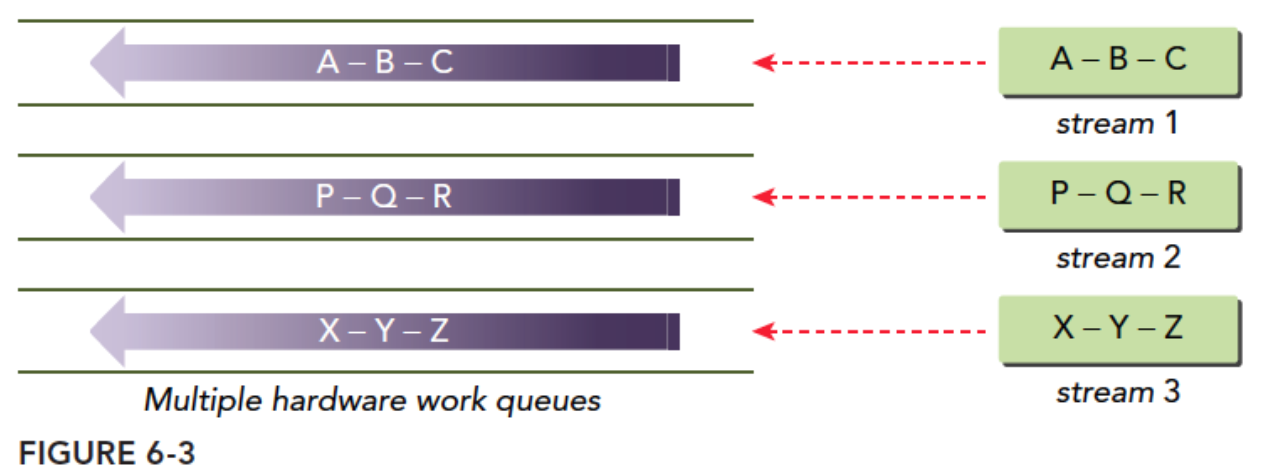
Hyper-Q技术
使用多个工作队列,解决了虚假的依赖关系。
流的优先级
优先级只影响核函数,不影响数据传输,高优先级的流可以占用低优先级的工作。
创建有指定优先级的流
1 | cudaError_t cudaStreamCreateWithPriority(cudaStream_t* pStream, unsigned int flags,int priority); |
参数说明
pStream: 流指针flags: 决定流是阻塞流还是非阻塞流。cudaStreamDefault:默认阻塞流。cudaStreamNonBlocking:非阻塞流。即可以和空流同时进行,对空流的阻塞行为失效。priority:优先级别。越接近0优先级越高。
查询当前设备的优先级分布情况
1 | cudaError_t cudaDeviceGetStreamPriorityRange(int *leastPriority, int *greatestPriority); |
leastPriority表示最低优先级(整数,远离0)greatestPriority表示最高优先级(整数,数字较接近0)
如果设备不支持优先级返回0。
CUDA 事件(Event)
事件的本质就是一个标记,可以使用事件来执行以下两个基本任务
- 同步流执行
- 监控设备进展
流中的任意点都可以通过API插入事件以及查询事件完成的函数,只有事件所在流中其之前的操作都完成后才能触发事件完成。
事件就像一个个路标,其本身不执行什么功能,就像我们最原始测试c语言程序的时候插入的无数多个printf一样。
事件声明
1 | cudaEvent_t event; |
创建事件
1 | cudaError_t cudaEventCreate(cudaEvent_t* event); |
销毁事件
1 | cudaError_t cudaEventDestroy(cudaEvent_t event); |
与流的销毁类似,如果回收指令执行的时候事件还没有完成,那么回收指令立即完成,当事件完成后,资源马上被回收。
将事件插入流中
1 | cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0); |
检查事件的操作是否在设备中完成
1 | // 阻塞主机线程直到事件被完成 |
记录两个事件的时间间隔
1 | cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop); |
这个函数记录两个事件start和stop之间的时间间隔,单位毫秒,两个事件不一定是同一个流中。这个时间间隔可能会比实际大一些,因为cudaEventRecord这个函数是异步的,所以加入时间完全不可控,不能保证两个事件之间的间隔刚好是两个事件之间的。
流同步
cudaStreamCreate创建的是阻塞流,意味着里面有些操作会被阻塞,直到空流中默写操作完成。举个栗子:
1 | cudaStream_t stream_1; |
上面这段代码,有三个流,两个有名字的,一个空流,我们认为stream_1和stream_2是阻塞流,空流是阻塞的,这三个核函数都在阻塞流上执行,具体过程是,kernel_1被启动,控制权返回主机,然后启动kernel_2,但是此时kernel_2 不会并不会马山执行,他会等到kernel_1执行完毕,同理启动完kernel_2 控制权立刻返回给主机,主机继续启动kernel_3,这时候kernel_3 也要等待,直到kernel_2执行完,但是从主机的角度,这三个核都是异步的,启动后控制权马上还给主机。
创建非阻塞流
1 | cudaError_t cudaStreamCreateWithFlags(cudaStream_t* pStream, unsigned int flags); |
flags:决定流是阻塞流还是非阻塞流。cudaStreamDefault:默认阻塞流。cudaStreamNonBlocking:非阻塞流。即可以和空流同时进行,对空流的阻塞行为失效。
如果前面的stream_1和stream_2声明为非阻塞的,那么上面的调用方法的结果是三个核函数同时执行。
隐式同步
所谓同步就是阻塞的意思,被忽视的隐式同步就是被忽略的阻塞,隐式操作常出现在内存操作上,比如:
- 锁页主机内存分布
- 设备内存分配
- 设备内存初始化
- 同一设备两地址之间的内存复制
- 一级缓存,共享内存配置修改
显式同步
常见显式同步
- 同步设备
- 同步流
- 同步流中的事件
- 使用事件跨流同步
显式同步常用函数:
阻塞主机线程,直到设备完成所有操作
1
cudaError_t cudaDeviceSynchronize(void);
同步流,阻塞主机直到完成
1
cudaError_t cudaStreamSynchronize(cudaStream_t stream);
测试一下流是否完成
1
cudaError_t cudaEventQuery(cudaEvent_t event);
同步事件,阻塞主机直到完成
1
cudaError_t cudaEventSynchronize(cudaEvent_t event);
测试一下事件是否完成
1
cudaError_t cudaEventQuery(cudaEvent_t event);
流之间同步
1
cudaError_t cudaStreamWaitEvent(cudaStream_t stream, cudaEvent_t event);
指定的流要等待指定的事件,事件完成后流才能继续,这个事件可以在这个流中,也可以不在,当在不同的流的时候,这个就是实现了跨流同步。
可配置事件
控制事件行为和性能
1 | cudaError_t cudaEventCreateWithFlags(cudaEvent_t* event, unsigned int flags); |
flags:cudaEventDefault、cudaEventBlockingSync、cudaEventDisableTiming、cudaEventInterprocess。
其中cudaEventBlockingSync指定使用cudaEventSynchronize同步会造成阻塞调用线程。cudaEventSynchronize默认是使用cpu周期不断重复查询事件状态,而当指定了事件是cudaEventBlockingSync的时候,会将查询放在另一个线程中,而原始线程继续执行,直到事件满足条件,才会通知原始线程,这样可以减少CPU的浪费,但是由于通讯的时间,会造成一定的延迟。
cudaEventDisableTiming表示事件不用于计时,可以减少系统不必要的开支也能提升cudaStreamWaitEvent和cudaEventQuery的效率
cudaEventInterprocess表明可能被用于进程之间的事件。
创建流间依赖关系
流之间的虚假依赖关系是需要避免的,而经过我们设计的依赖又可以保证流之间的同步性,避免内存竞争,这时候我们要使用的就是事件这个工具了,换句话说,我们可以让某个特定流等待某个特定的事件,这个事件可以再任何流中,只有此事件完成才能进一步执行等待此事件的流继续执行。
1 | cudaEvent_t * event=(cudaEvent_t *)malloc(n_stream*sizeof(cudaEvent_t)); |
这时候,最后一个流(第5个流)都会等到前面所有流中的事件完成,自己才会完成。
流回调
流回调是一种特别的技术,有点像是事件的函数,这个回调函数被放入流中,当其前面的任务都完成了,就会调用这个函数,但是比较特殊的是,在回调函数中,需要遵守下面的规则。
- 回调函数中不可以调用CUDA的API
- 不可以执行同步
流函数
1 | void CUDART_CB my_callback(cudaStream_t stream, cudaError_t status, void *data) { |
将流函数加入流中
1 | cudaError_t cudaStreamAddCallback(cudaStream_t stream,cudaStreamCallback_t callback, void *userData, unsigned int flags); |
CUDA常见函数
cudasetdevice(n)
cudaSetDevice函数用来设置要在哪个GPU上执行,如果只有一个GPU,设置为cudaSetDevice(0)
cudaDeviceReset()
调用核函数时,这句话如果没有,则不能正常的运行,因为这句话包含了隐式同步,GPU和CPU执行程序是异步的,核函数调用后成立刻会到主机线程继续,而不管GPU端核函数是否执行完毕,所以上面的程序就是GPU刚开始执行,CPU已经退出程序了,所以我们要等GPU执行完了,再退出主机线程。
cudaDeviceSynchronize()
想要主机等待设备端执行可以用下面这个指令。
cudaMalloc(void **devPtr, size_t nByte)
cuda中申请分配显存的函数,注意传入参数,第一个传入参数是一个双指针类型,第二个是一共申请的内存大小(字节数),重点理解第一个传入参数。示例如下。
1 | float *device_data = NULL; |
第一行在主机端声明了一个指针,指向我们需要操作的数据。第二行计算需要申请多少字节数。第三行&device_data传入的是声明指针的地址,也就是指针变量的地址,再将其强制类型转换成指针的指针,这样可以在函数内部改变**中指向的*的值,这个值也即是device_data这个指针变量,而不是它指向的值。此时我们可以将显存中申请的数组的首地址赋值给device_data(不是它指向的值),就可以完成内存申请了。
cudaMemcpy(d_a, h_a, nByte, cudaMemcpyHostToDevice)
函数作用:实现主机和设备的内存复制。是同步的,需要执行完毕后才能进行下一步。
参数含义:复制的目标,复制的源头,复制的字节大小,复制的类型,分别有cudaMemcpyHostToHost,cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,cudaMemcpyDeviceToDevice,代表内存复制的方向。
cudaMemcpyAsync(void* dst, const void* src, size_t count,cudaMemcpyKind kind, cudaStream_t stream = 0)
函数作用:与cudaMemcpy相似,只不过是异步的。cudaMemcpyAsync发出命令后主机就不等待了。
参数含义:复制的目标,复制的源头,复制的字节大小,复制的类型,分别有cudaMemcpyHostToHost,cudaMemcpyHostToDevice,cudaMemcpyDeviceToHost,cudaMemcpyDeviceToDevice,代表内存复制的方向。stream表示流,一般情况设置为默认流。
cudaMemcpyToSymbol(const void *symbol, const void * src, size_t count, size_t offset, cudaMemcpyKind kind)
函数作用:把主机上申请的常量内存复制到设备的常量内存中。
参数含义:复制的目标、源主机地址、复制的字节数、偏移量(不设置默认为0)、传输方向(一般为cudaMemcpyHostToDevice)
cudaFuncSetCacheConfig(const void * func,enum cudaFuncCache)
函数作用:设置SM中一级缓存和共享内存共享的片上内存。这个函数可以设置内核的共享内存和一级缓存之间的比例。
参数设置:cudaFuncCache参数可选如下配置
1 | cudaFuncCachePreferNone//无参考值,默认设置 |
cudaMemcpyToSymbol(const void* symbol,const void *src,size_t count)
函数作用:初始化常量内存,从src复制count个字节的内存到symbol里面,也就是设备端的常量内存,也可以将内存拷贝到全局内存中。
参数含义:symbol设备端常量内存,src主机端内存,count复制的字节数。
注:这个函数是同步的,会马上被执行。
cudaMemcpyFromSymbol(const void* symbol,const void *src,size_t count)
函数作用:从symbol复制count个字节的内存到src里面,也就是将设备端的变量复制到主机端。
参数含义:symbol设备端常量内存,src主机端内存,count复制的字节数。
cudaGetSymbolAddress((void**)&dptr,devData)
函数作用:获取设备端变量devData的地址。
参数含义:dptr设备端变量地址,这个变量是指针的指针devData设备端变量。
cudaError_t cudaMemset(void *devPtr,int value, size_t count)
函数作用:这一段内存的值都分配为value
参数含义:devPtr要被分配的地址,value被赋值的值,count字节数
CUDA工具
Nsight
Nsight Compute
Nsight Compute通过用户界面和命令行工具提供详细的性能指标和API调试。此外,它的基线特性允许用户在工具中比较结果。NVIDIA Nsight Compute提供了一个可定制的、数据驱动的用户界面和度量集合,并且可以通过分析脚本对后处理结果进行扩展。
GUI模式
使用时要以管理员权限运行,否则会出现GPU访问权限的问题
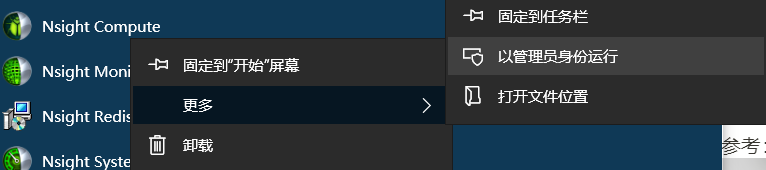
连接页面选择连接的设备ip和可执行文件的位置
点击
Run to next kernel
此时程序暂停到核函数前,然后点击
Profile Kernel获取详细信息
注:只有程序暂停到核函数前,
Profile Kernel才可以点击。点击
Page的不同选项,可以得到对应信息
CLI模式
使用前需要配置好环境变量
基本使用:要收集目标应用程序中所有内核启动的“基本”集,在CUDA可执行文件目录下,以管理员权限打开该目录,输入
1 | ncu -o profile xx.exe |
常用命令
I/O
-o参数:指定输出的分析报告.ncu-rep的路径以及名称;-f参数:如果ncu指定了-o参数、输出分析报告,分析报告指定的路径下有同名文件,可以指定-f参数强制将同名文件覆盖,否则ncu会报错停止运行;—-log-file参数:将ncu在运行时产生的log存在指定路径的文件中;如果在ncu运行时不指定
-o参数,则不会产生分析报告,并会将所有的分析结果打印在终端中,同样可以通过设置参数来决定终端中显示什么样的信息:—-page参数:选择在终端中打印分析报告中的哪部分信息,一般使用details来打印用户指定采集的分析指标的详细信息;—-csv参数:将终端中打印的Kernel的分析信息组织成csv格式的输出,方便导出到文件中进行后续的数据分析。ncu还可以使用
—-import将之前生成的分析报告读入,然后根据—-page、—-csv等参数的设置将分析报告在终端中打印出来。Filter
ncu在运行时可以根据参数的设置对要profiling的Kernel、进程、设备等进行过滤,首先来看Kernel的过滤:
—-kernel-name参数:支持根据准确名称或正则表达式来过滤需要进行profiling的Kernel-c参数:限制程序中进行profiling的Kernel函数的总数-s参数:跳过程序中的前N个Kernel后再进行profiling再来看一些ncu对于需要进行profiling的进程进行选择的参数:
—-target-processes参数:选择ncu目标进行profiling的进程,application-only选项只会让ncu对根进程进行profiling(然而这些根进程一般都只是启用后续的程序用的,捕捉不到什么有用的Kernel信息),all选项会对根程序产生的所有子进程进行profiling,一般来说我们选择这个选项。—-target-processes-filter参数:支持通过准确名称或正则表达式来过滤ncu需要进行profiling的进程,具体可以参见Nvidia文档中的说明。最后是ncu对于需要进行profiling的设备进行选择的参数:
—devices参数:指定需要使用ncu进行profiling的(GPU)设备编号(默认是所有参与的GPU),Nvidia官方推荐在每个Node中只使用一个设备进行profiling,否则可能会引发程序的stallProfile Section
使用ncu进行profiling时可以获取关于Kernel各个方面的指标,但是如果运行时需要获取所有的指标的话就可能导致ncu运行的时间非常长,如果只想获取到特定方面的指标,可以通过参数
—-section指定在profiling时需要采集的特定方面的指标,这样就可以有效减少不必要的profiling时间,关于所有的section的选项可以在Nvida官方文档中进行查看,这里列举一些常用的section进行说明:MemoryWorkloadAnalysis: 可以让ncu对Kernel在内存利用方面的指标进行profiling,具体包含最大吞吐率、最大带宽利用率等指标;ComputeWorkloadAnalysis:Detailed analysis of the compute resources of the streaming multiprocessors (SM), including the achieved instructions per clock (IPC) and the utilization of each available pipeline. Pipelines with very high utilization might limit the overall performance.指标示例:

Occupancy:Occupancy is the ratio of the number of active warps per multiprocessor to the maximum number of possible active warps. Another way to view occupancy is the percentage of the hardware’s ability to process warps that is actively in use. Higher occupancy does not always result in higher performance, however, low occupancy always reduces the ability to hide latencies, resulting in overall performance degradation. Large discrepancies between the theoretical and the achieved occupancy during execution typically indicates highly imbalanced workloads.
Nsight System
所有与NVIDIA GPU相关的程序开发都可以从Nsight System开始以确定最大的优化机会。Nsight System给开发者一个系统级别的应用程序性能的可视化分析。开发人员可以优化瓶颈,以便在任意数量或大小的CPU和GPU之间实现高效扩展
用户手册地址:User Guide — nsight-systems 2024.5 documentation (nvidia.com)
GUI模式
与Nsight Compute类似,指定好可执行文件目录后,点击开始即可。
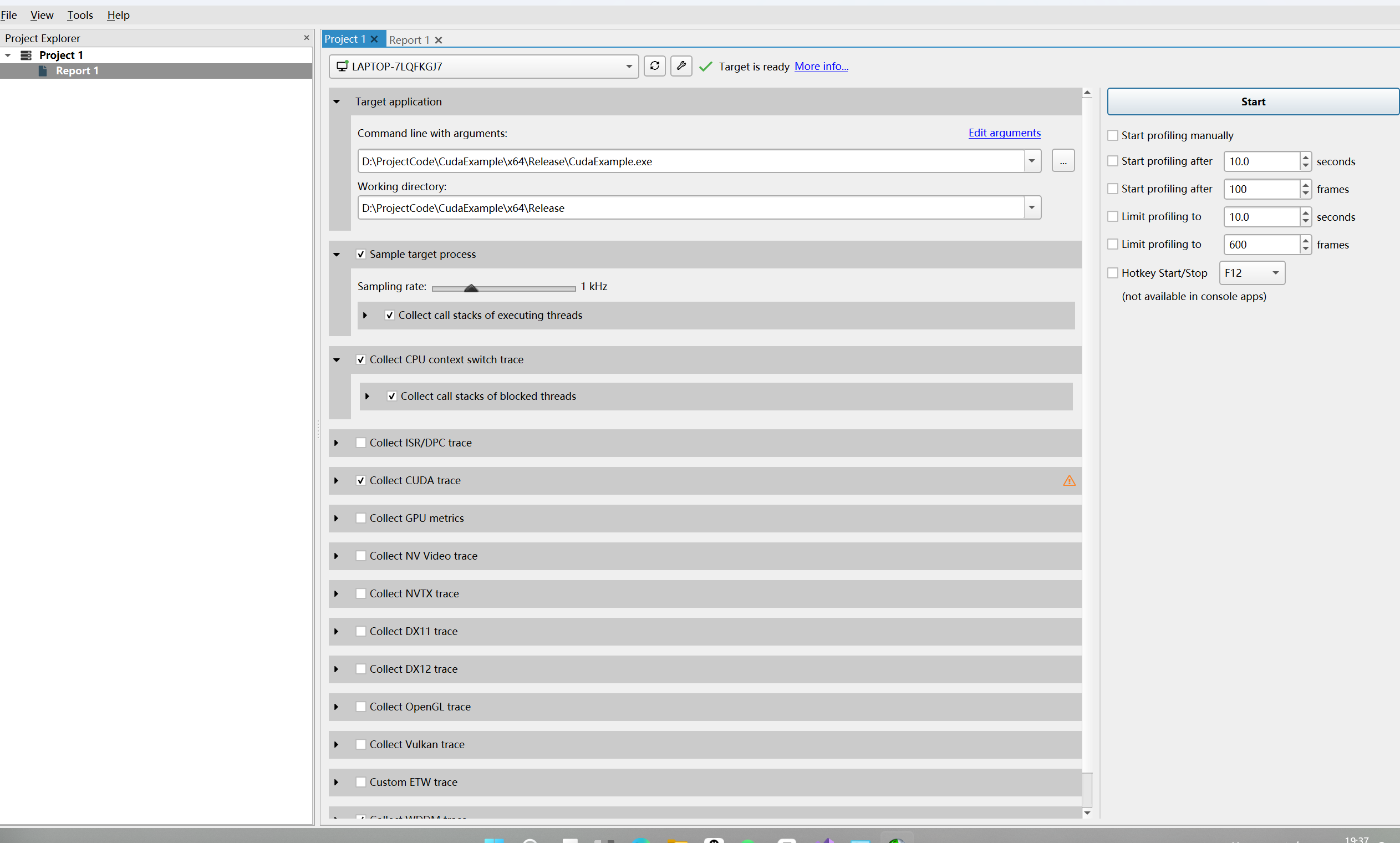
CLI模式
必须以管理员身份在 Windows 上运行 CLI。
命令行选项
1
nsys [global_option]
or
1
nsys [command_switch][optional command_switch_options][application] [optional application_options]
生成分析结果文件
1
nsys profile –t cuda,osrt,nvtx –o baseline –w true python main.py
-t后面跟定的参数是我们要追踪的API,即需要CUDA API,OS runtime API以及NVTX API-o给定的是输出的文件名称-w后面表明是或否要在命令行中同时输出结果python main.py为程序的执行命令- 将导出的baseline输出文件下载到本地,并拖拽到本地的Nsight System窗口即可获取性能结果展示。
相关链接
CUDA编程 - Nsight system & Nsight compute 的安装和使用 - 学习记录-CSDN博客
NVIDIA Compute Sanitizer
问题
Q1 CUDA编程中引入头文件和链接器的问题
要点1: 在项目属性中添加CUDA的bin文件
要点2: 在项目属性中添加CUDA的lib文件
要点3:自定义生成依赖项(此处不要忘记)
具体步骤参考:vs2019 在C++项目中添加cuda配置(#include “cuda_runtime.h“等飘红问题解决)_vs2019 c++ cuda-CSDN博客
Q2 CUDA 开发中的设备与主机
通常主机指CPU,设备指GPU
Q3 核函数中可以使用C++输入输出流吗(cout、cin)
核函数中不可以使用cout和cin,但是.cu文件中其他函数(非核函数)可以使用cout和cin。
Q4 CUDA正确运行用户名
CUDA运行成功需要用户名为英文,不能出现中文路径名。
Q5 VS+CUDA新建项目没有CUDA选项的问题
一般来说这种情况是由于先装CUDA后装VS导致的,解决办法可以参考:VS+CUDA 新建项目里没有CUDA选项(附详细图文步骤)_cuda visual studio integration没有勾选,怎么重新下载-CSDN博客